


傲世皇朝资讯
实施顾问的话你得蛰伏几年,但是越老越吃香,越老待遇越高 级别越高相对是管理了比算法和开发都轻松,
概念而已,不要当真。
给大家分享下阿里巴巴的数字供应链吧。
零售行业是阿里巴巴的主营业务,零售强依赖于供应链,阿里巴巴数字供应链聚焦零售供应链全链路,所建设的零售操作系统已经成为集团重要基础设施。阿里围绕人货场,构建了一套从数字化到智能化的供应链产品体系。从业务的支撑来说,阿里巴巴数字供应链事业部支撑了整个集团 20 多个 BU 的供应链业务,同时面向 6 亿多的消费者,有近 5 万多家外部商家也在基于这套系统为消费者提供服务,比如,天猫超市,天猫国际,淘宝,天猫,零售通,消费电子以及海外 Lazada 等上层业务,都在阿里巴巴智慧供应链的支撑下高质量运转。
本次分享将围绕以下四个主题展开:
- 供应链数字化解决方案
- 供应链智能化解决方案
- 自动预测技术 Falcon
- 自能预测系统 Alibaba DChain Forecast
--
分享嘉宾|陈叶芬博士 阿里巴巴 供应链引擎产品负责人
编辑整理|卢俊 华为云
出品社区|DataFun
首先和大家分享下供应链数字化和智能化发展的背景。对实战和案例感兴趣小伙伴可跳过此part。
大多数企业在做供应链业务决策的时候,虽然处于不同阶段的企业面临的难题会不同,但基本上可以归纳到以下三层。
① 数据层
供应链向上需要支撑多元化的销售渠道,向下需要链接多渠道供应商,所链接的系统种类较多,导致支撑供应链决策的数据来源较为复杂,这为供应链决策带来第一层挑战——数据层。如何做到数据全、数据及时、数据一致(来自多系统的数据可对话),是供应链智慧决策要解决的第一层问题。总的来说,数据层是要让我们在做决策的时候有数可依,而且这个数是准确的,正确的,科学的。
② 分析层
当积累了丰富多样的数据指标之后,我们怎么能让数据高效率地去发挥出业务价值?怎么让涉及多个部门业务的数据或者是多个渠道的数据,通过对它们有机地串联,形成能指导业务方向,帮助解决业务问题,分析层应该给我们一个解决方案,实现能够帮助业务及时准确地去洞察到问题或者说机会。
③ 决策层
当数据层和分析层构建好之后,面对庞大规模和不同层级的业务问题,如何将数据和分析转化成决策能力?这是企业通常面临的第三层问题。第一步是靠人工决策,但随着生意规模的发展,SKU 越来越丰富,人处理问题的局限性就被暴露出来了,一方面处理能力有限,另一方面决策质量依赖人的个体经验,一旦岗位变动就难以持续继承。这就发展第二步,智能决策的应用。在智能决策阶段,我们有两点思考:第一,我们希望在算法驱动或技术驱动的体系下,决策能越来越科学,而且未来可以被复用和可以持续迭代;第二,我们要自动化,这样的话才可以规模化,而不靠人非常低效地去做这些完全没有保障的决策。
以上就是我们对整个供应链决策不同层难题的剖析。

① 供应链部门所处位置
任何一个企业都至少有三个部门。第一个部门是研发部门,它负责整个产品的管理,设计好的产品出来。第二个部门是营销部门,它负责整个需求的管理,然后让产品能卖个好价钱。第三个部门就是供应链部门,它负责成本和服务质量管理,去研究怎么以合适的成本和速度把产品生产出来,再按期交付给客户。所以大家可以看到供应链这个部门是偏后台的,但对于很多行业来讲,它的管理水平决定了这个企业能不能持续化,扩大化发展下去。
② 供应链的发展层次
从整个供应链的发展过程来看,它也分为几个阶段:从最原始的供应链,往上发展出初级供应链,具有跨部门的分工和流程的协同;再继续发展为整合供应链,继续往上是要构建出一个供应链上的领导力来协同整个链条;最后发展到智慧供应链,如何应用新的技术,去帮助我们更高效率地去实现整个供应链的低成本,高稳定,以及高服务质量。
③ 智慧供应链需要具备什么能力
最高层级的智慧供应链应该具有哪些能力特征?通过思考和实践,我们认为它至少要具备三个方面的能力。首先是可视的,就是数据要准确,比较完整地通过数据反映供应链的现状和变化的情况。其次是可感知的,当它遇到问题,我们能够及时地收到反馈并报警。最后是能够自我去调节,去应对市场变化,也就是我们常谈到的韧性供应链或者柔性供应链,如何在变化多端的市场环境下,能够快速的应对变化,稳定地输出服务质量。
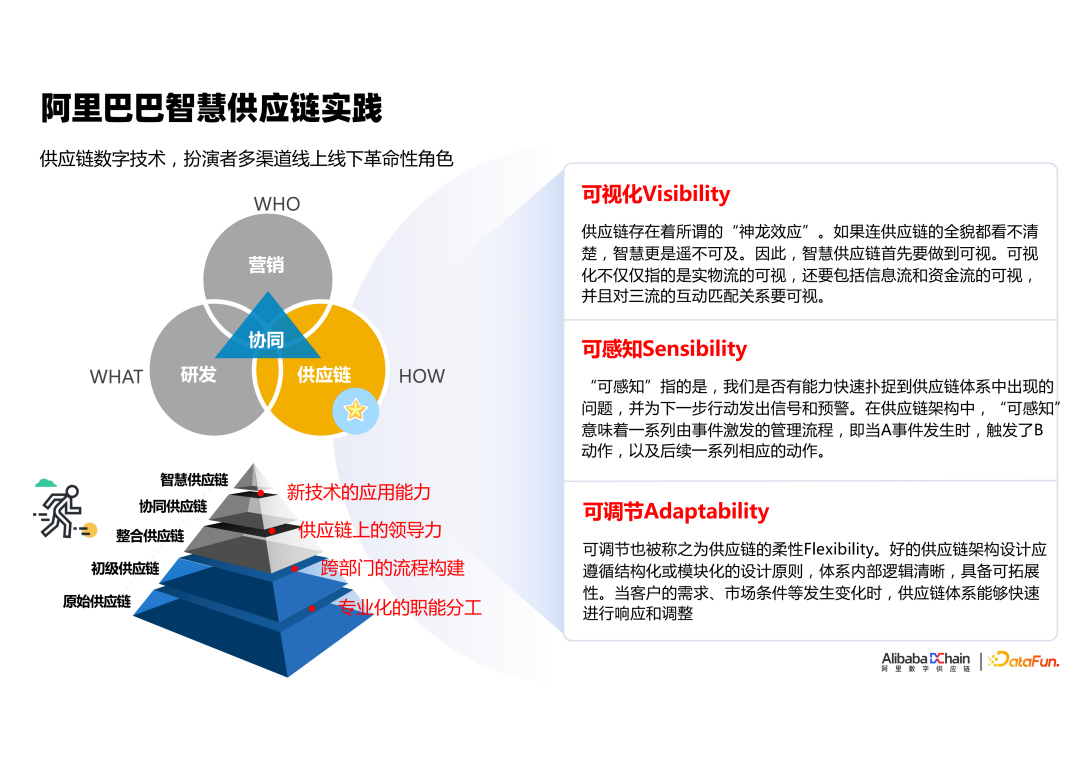
① 全渠道数字化(可视化)
第一个阶段是全渠道可视化。我们的业务会有很多渠道:比如一个商家进来,我们可能会有像零售通这样的业务 ToB 的,我们也会有像天猫超市这样 ToC 的业务,同时我们可能还会有国际进口,国际进口转大贸等业务。我们第一步是想要把这些业务都可视化出来,并且聚焦在如何对不同渠道的货品,实现一盘货的管理,提升库存的效率。
② 全链路数字化(可感知)
下一个阶段是整个链路都要实现数字化,包含采购、库存入库、调拨、出库、履约、消费者体验全链路各个环节,再每个环节实现异常自动识别,主动报警。
③ 智能决策(可调节)
在第三个阶段需要攻克如何将智能决策落地,并且实现数据驱动的决策,让机器学习、运筹优化、全链路仿真优化技术在业务场景中发挥价值,提高业务效率,把规模化做得更大。
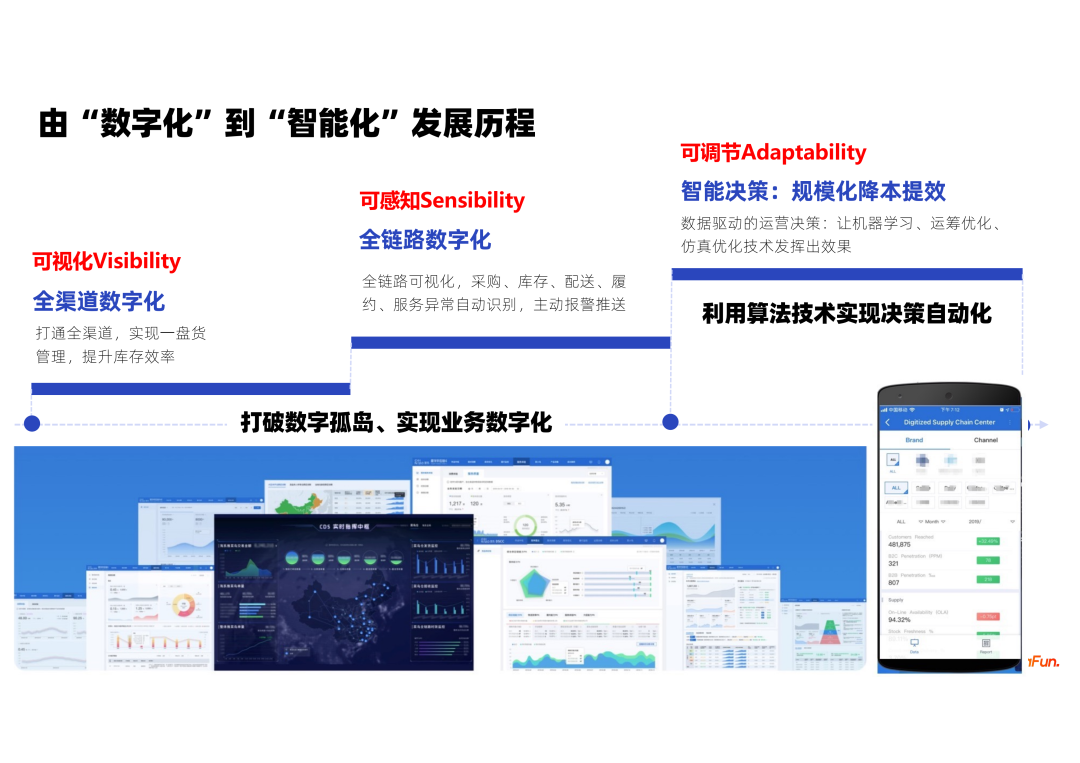
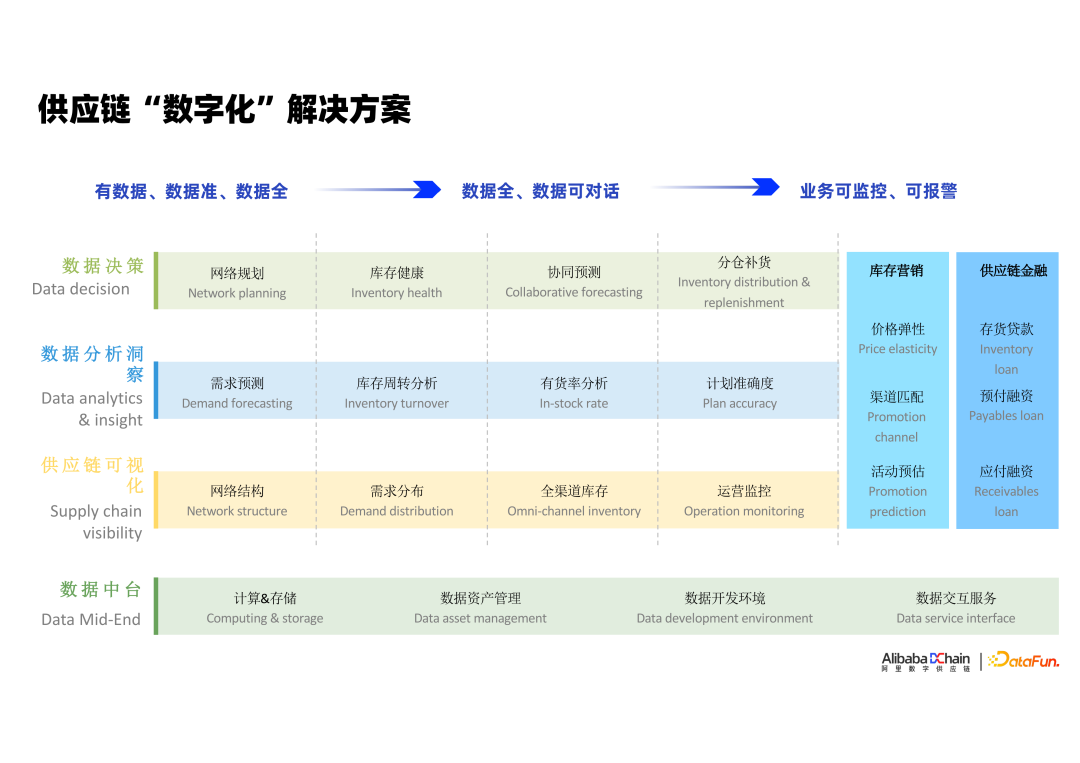
① 数据中台
数字化的第一步是数据层的建设,这一步核心是保障好数据质量,在准确率、及时性、完整度上提升到一定水平。
② 供应链可视化
接下来围绕供应链各环节,构建出一套能反映供应链的运转现状的业务指标,通过将业务指标的有机串联,实现供应链的可视化。
③ 数据分析洞察
构建分析洞察的能力时,我们本质上是要构建出自动分析诊断能力,或者是对需求的感知能力,具体包含需求预测,库存周转分析,有货率,计划准确度的分析等。
2. 案例分享
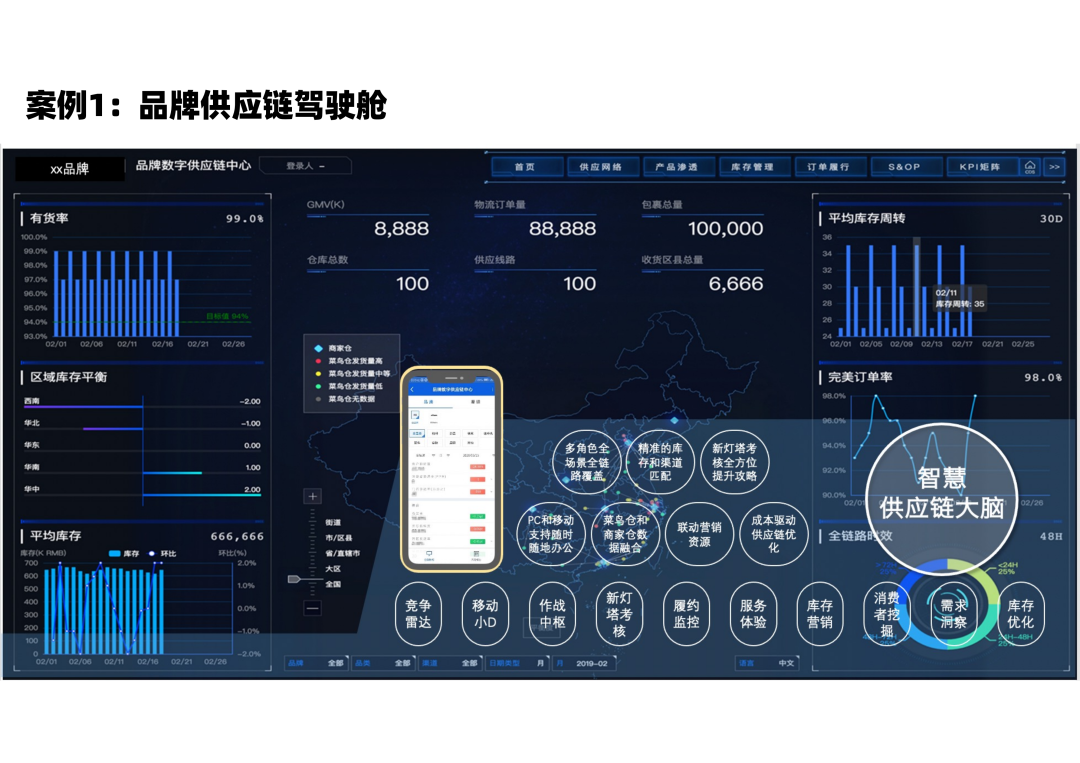
① 案例1
分享一个我们曾经做过的数字供应链案例,某个品牌的数字供应链。可以看到,站在企业的视角,会有不同的渠道,不同的品牌、不同品类。这些不同渠道、品牌和品类很有可能是由不同部门管理,过往线下汇总数据时,很有可能不同部门的数据统计口径不同,难以整合,通过供应链数字化建设,能够实现跨部门管理指标一致,并且自动计算汇总。另外,企业不同管理层级对数据颗粒度的需求也是不一样的,管理层更关注整个生意的中长期趋势,执行层更关注更细粒度短期数据,供应链的数字化能以非常低的成本批量生成,并且自动更新。
围绕零售行业,企业最关注的是货的效率,在架率反映供应链的供给服务水平,周转率反映货品的供给效率。另一块是,在整个供应网络中,产品到消费者手上的体验如何?比如,完美订单订单率能到多少?全链路的时效是多少?产品在全国的渗透率的情况如何?以及在订单履约的不同阶段,遇到了哪些异常和超时?通过对供应链的数字化,形成一套贯穿企业从上到下高效率地掌握供应链运行现状和发掘并解决问题的管理机制。
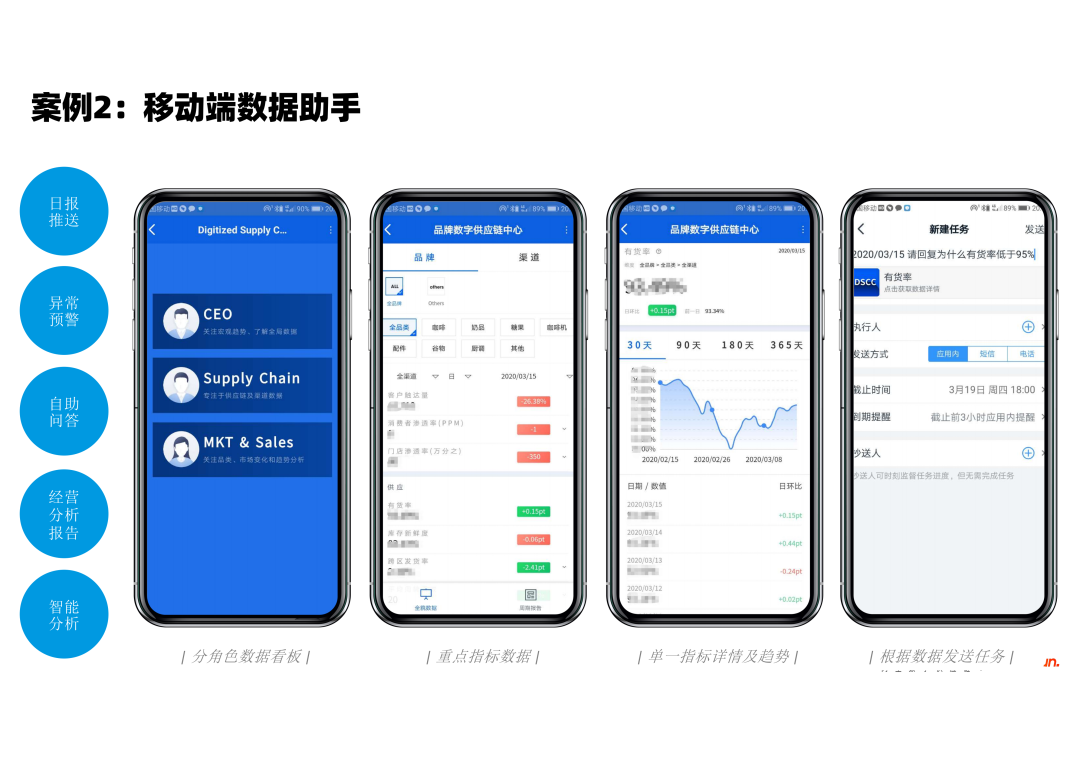
② 案例2
在移动办公的大趋势下,我们基于钉实践出了一套移动端的供应链管理助手。面向公司不同的角色,分 CEO、供应链部门和销售部门,分别展示不同的数据指标,但是这些数据来源都是一处,数据t-1同步更新,实现所有人员都基于同一份业务数据决策。
对于重点指标数据的话,可以实时监控它的变化情况,近期发展趋势,而且我们把整套系统和工作流做了协同打通,当供应链总监发现了一项业务指标变差后,可以一键督促执行层员工处理问题,并可跟踪整个治理进度,以及完成的情况。
--
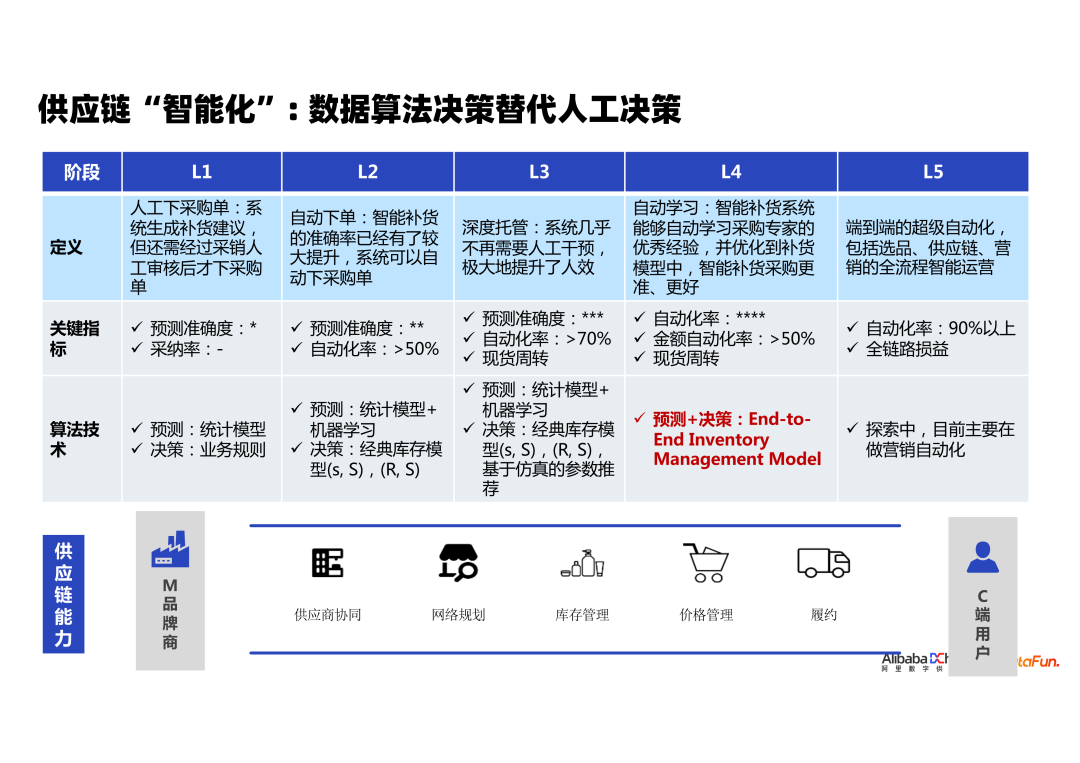
供应链从数字化走向智能化过程中,根据智能化水平的不同,可分成哪些阶段?经过了不断的实践和修正,我们认为,供应链的智慧化进程可以划分为五个阶段。
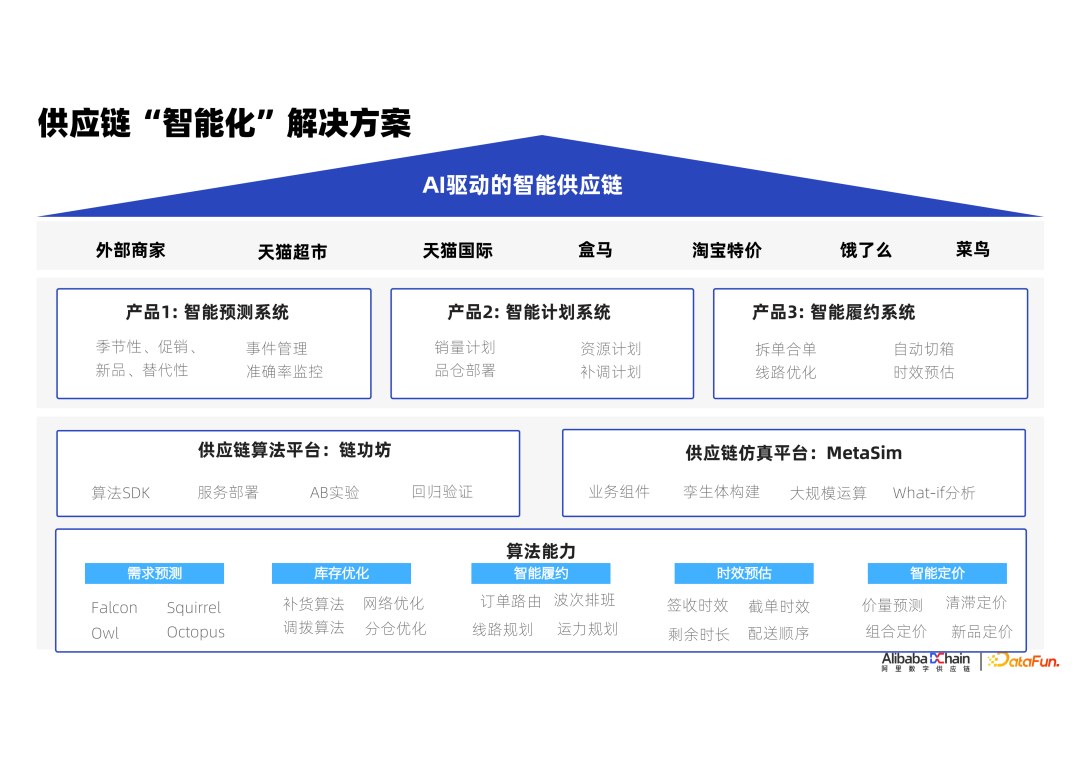
要支撑供应链智能化发展,底层应该具有哪些能力才能够支撑我们不断变化的业务迭代、新业务的拓展,以及我们怎么才能快速地把智能化这套方案落地?经过我们多年的实践,积累出了三层解决方案。
① 第一层是算法能力
在智能化这条路上,算法能力是基础,算法的应用场景能够覆盖到供应链的各个环节。比如,在影响供给效率的环节上,我们经常提到的需求预测能力,库存优化相关的补货算法,对整个物流网络的优化,或者是对整个库存网路的调拨算法,都涵盖了利用大规模计算来实现全局最优的逻辑;在影响消费者体验环节上,如何确定每个订单的履约路由,持续不断地让消费者获得非常快速的确定性履约的能力,一笔订单付费后,如何发配到不同的仓,不同的门店,让哪家配送商来执行订单履约,往下的话就是仓库内分拣、打包、出库波次的排班,或者是我们的整个配送线路、运力的规划,这些点都在这个算法能力大图里面。还有对时效的预估,如何给消费者一个确定的履约时效透传,大家在淘宝天猫上购买的商品,或者饿了么上购买的商品,你看到的他所预估的时效是否跟它实际能达到的接近,这个时效透传是在尽最大努力为消费者提供确定性的送达时间信息;最后是面向上层的智能定价体系,这也属于货品和商品之间的一个联动。如果说库存优化在就是inbound的这个链路上去做库存的控制优化,那么智能定价其实是在做 outbound 的这个链路上的优化。
② 第二层是工程平台
这一层,我们考虑的是,算法能力如何高效率地在业务系统中发挥出价值?我们有两个投入很重资源建设的平台,他们已成为整个智慧供应链的基础设施。第一个是供应链算法平台,它承载了所有供应链算法的部署、运行、实验和效果监控能力;另一个是供应链仿真平台,大家都知道供应链是一个很复杂的系统,哪怕是我们把一个简单场景,modellin成一个整数规划或者一个混合规划问题,当我们去调用求解时,会发现,可能就解不出来,或者说因为你的模型无法考虑所有因素,导致结果在实际运用中不像建模时的业务效果那么好。这时候,我们发现,供应链仿真能克服这个问题,是我们应用非常高频的一种方法,我们通过构建整个供应链的仿真环境,计算不同的策略运行会给整个链条带来什么样的影响。
③ 第三层是业务系统
再往上,我们这些能力输出到不同的业务系统中,典型的有,预测系统,计划系统,履约系统等,使这些能力在不同业务场景中发挥价值,这些是我们对整个供应链智能化底座的设计。
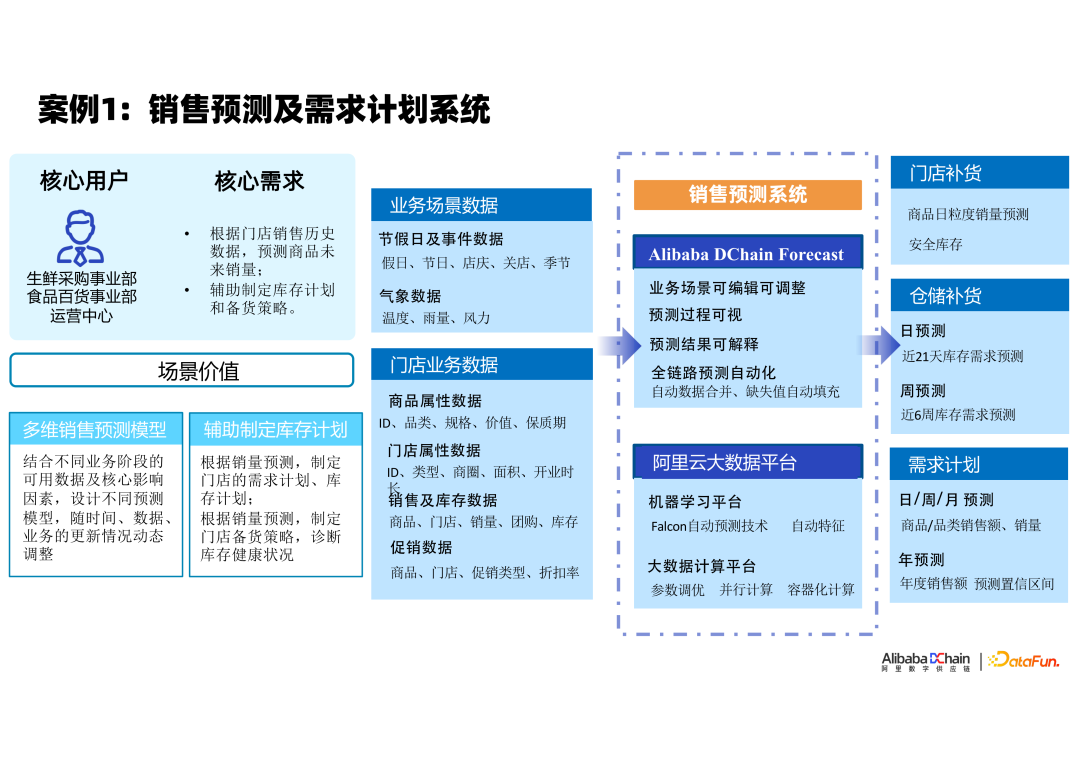
① 案例1
第一个案例是如何构建一个供应链预测系统,进而支持更好的供应计划?大家都知道供应链是带有很多不确定性的,因为它有 lead time,它有多个供应节点,所以我们经常称,销量预测是我们应对供应链不确定的第一套防线,也是我们整个智慧供应链的基础。比如,在这个场景里,核心用户是采购事业部或者是运营人员,他需要根据历史数据来预测商品未来的销量,需要系统辅助运营人员制定一个合理的库存计划和备货策略,来应对未来的不确定。
第一步,分析系统的输入输出:系统需要输出多维度商品销量预测结果,支撑做销量预测的数据源,不同的业务场景可能不太一样,一定会包含的是本身的业务数据,商品或者门店的历史销量数据,相应的促销事件,商品的关联或者替代关系,这些都是我们做预测的重要输入,此外,还有节假日,线下的门店,店庆,关店,季节性等,这些对线下预测来说,都是非常敏感的特征输入数据,有些业务场景甚至会涉及到温度、气象等数据。
接下来,销售预测系统基于所输入的业务数据输出预测结果。大家都知道,预测确实它不是一件好做的事情,不同的场景下能达到的准确率都是完全不一样的,此外,在整个预测的过程中,我们怎么去让整个预测白盒化,可解释,可协同,也是我们构建预测系统时需要重要考虑的一个点。
最后,这些系统输入的数据,我们以不同的时间粒度或者以不同的频次,推送到系统上。
这是在销量预测场景上,我们的一个案例。
② 案例2
第二个案例是产销计划协同系统。当有了销量预测,如何制定库存计划,如何制定采购计划,如何制定生产计划,这些计划都是由不同部门的人负责,如何通过一个系统协同这些不同岗位人员,是产销计划协同系统核心要解决的问题。从刚刚的描述中,大家看以看到,协同是出现的一个高频词,相比较其他系统,这个系统更偏重多角色的协同。从系统目标来看,它的价值也是聚焦在提升库存价值上,提升整个库存的效率,降低库存流转链条中的物流的成本或者人工处理成本。
这部分是我们研发的产销计划协同系统,在服务外部商家的一个案例。
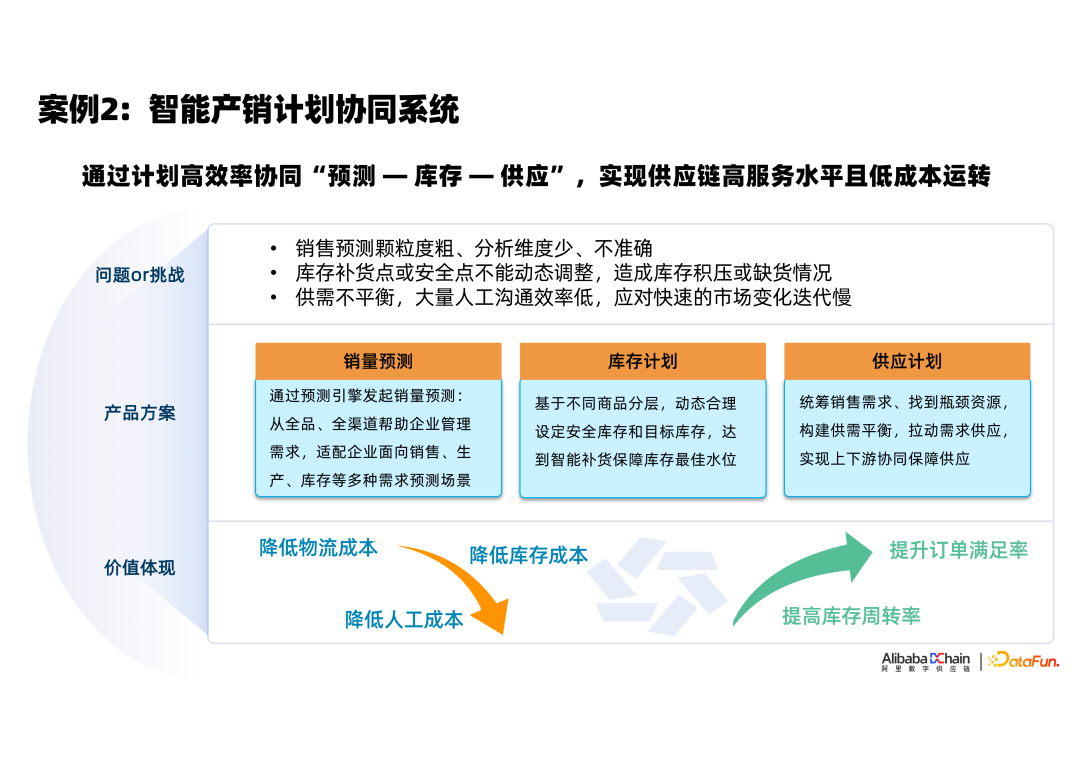
③ 案例3
最后分享的一个案例,一体化智能供应链计划系统解决方案。我们可以感觉到,不管是在做库存计划,还是库存分布优化,我们都在围绕需求,针对需求的变动,如何分解和消化,如何提前部署库存,尽可能服务好需求侧 。
在对系统做整体规划时,需要考虑三层用户价值。第一层是为经理层提供年度计划执行和协同能力,属于业务战略规划,通常要做的事年度销售预算和计划,或者是整个流通和运输网络应该如何搭建,战略层的决策内容将会影响整年甚至更长期供应链运转;第二层是为中层提供基于战略层拆解到战术层计划的能力,通常需要制定的月粒度的销售和库存计划;第三层是基于战略和战术层的规划,为一线执行者提供周/日时间粒度上的行动计划,明确出一线执行者的行动内容,如补货SKU、补货量、补货方式等。
对这个系统的要求是具备感知、引导、联动和协同的能力。宏观上,对需求的波动有感知,通过销售和库存之间的联动,来引导需求、塑造需求;生产计划系统负责承接需求,与采购系统之间的联动来快速应对市场需求变化。
最后的话想和大家分享下阿里在预测上的进展。
对供应链来说,预测是一个非常重要的主题,我们一直在致力于打造高稳定性、高精度的预测能力,这里结合阿里的业务实践,分享阿里是如何对预测技术持续迭代。
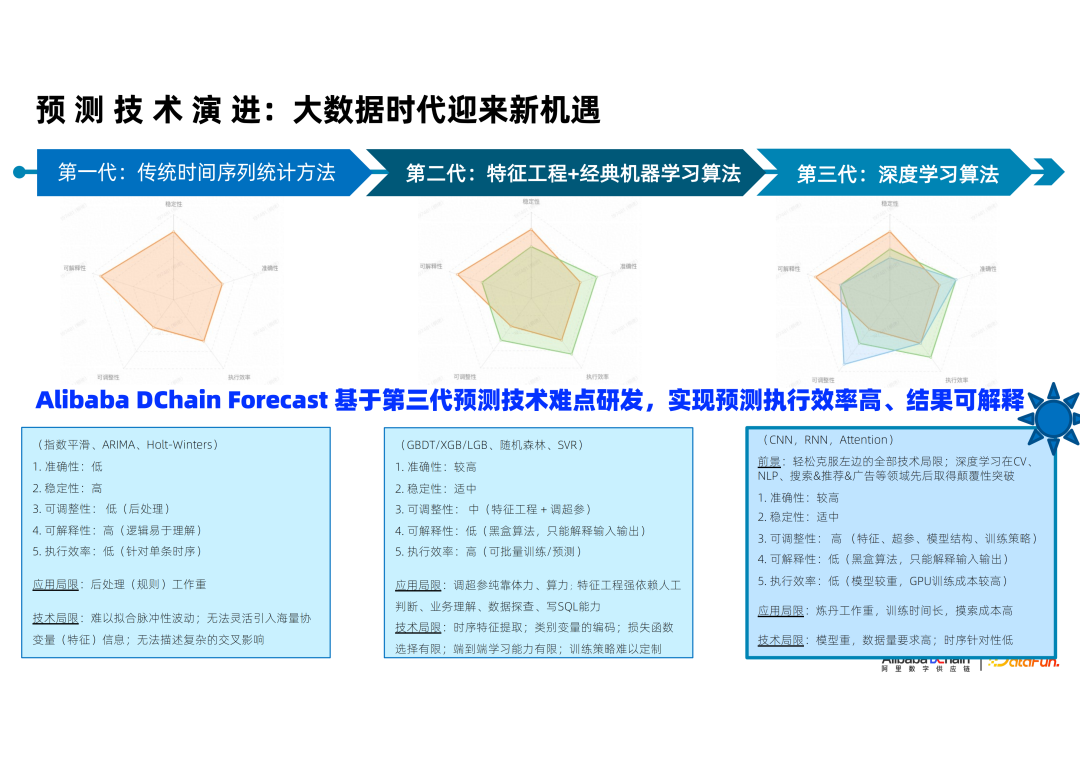
1. 自动预测技术演进
首先和大家看一下自动预测技术的发展历程。最初的预测技术以传统基于数据统计的预测方法为主,比如,我们常讲的 EMA、ARIMA 、Holt-winters 等。接下来,随着机器学习的发展,有像 LGB、随机森林的机器学习驱动的预测算法。再往后,发展出了一些深度学习的算法,代表性的有 TFT、Deepar 等。
对于我们的业务来说,最大的特点是数据量会很大,很多场景需要对万级,甚至到百万级时序做预测。虽然传统时序预测模型在有小部分场景可以取得不错效果,但是在应对波动业务的效果稳定性上不足。经过大量实际业务验证,深度学习类算法虽然技术投入要求大,但是在应对不断变化的市场上,预测稳定性和精度都优于前两代算法。
针对零售供应链行业对预测的可解释性和执行效率要求,我们基于深度学习理论框架自研了第三代预测算法,已经克服了部分技术缺陷,比如,它的预测是黑盒,可解释性不好,那么我们怎么去把它的可解释性做出来。
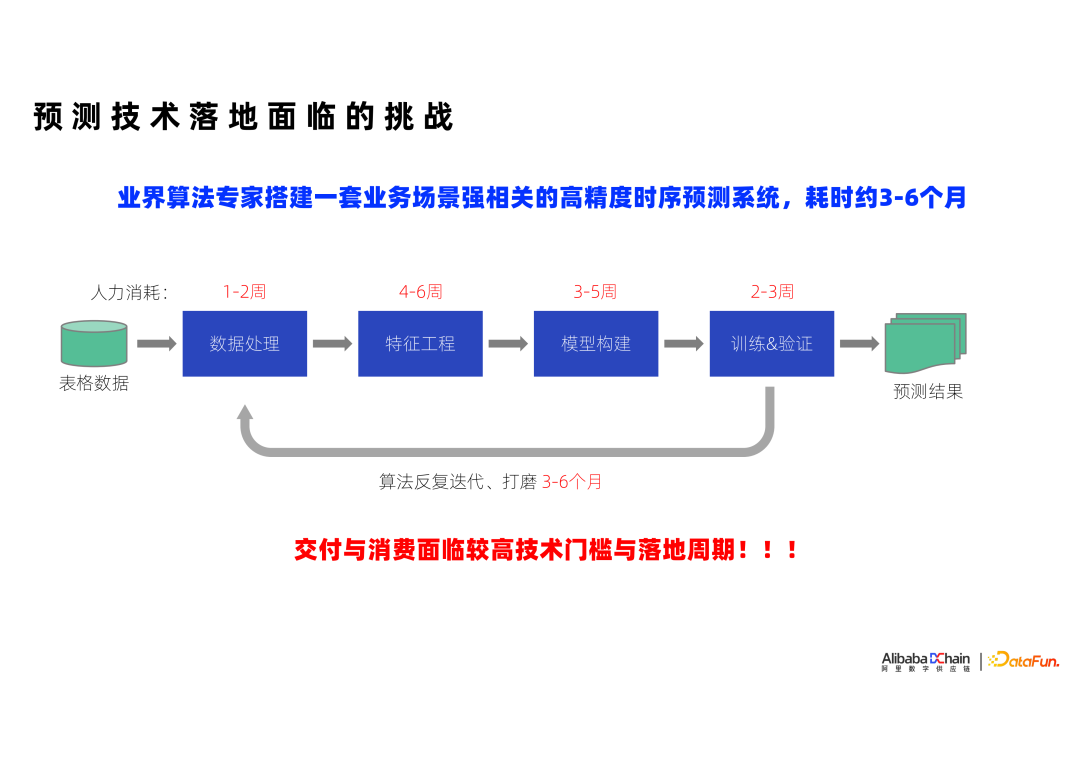
2. 预测技术落地面临的挑战
我们在研发预测技术的时候,希望朝着自动化的趋势来做。为什么呢?因为我们在实际业务应用时发现:业务永远是在变的。在业务不断变化的这一背景中,我们如何能做到高效率地服务他们?要是每新添一项业务,我们就要新招一批人来支持,对于公司而言,人力成本的负担太重了,所以我们希望在自动化上也有一些突破,通过自动处理来解决这一问题。
3. 全自动预测技术 Falcon
在这样的背景下,我们研发了全自动预测技术 Falcon,经过持续的跟踪,验证了这套技术比前两代预测技术表现更先进,不管是精度上,还是稳定性上,都更好。未来,我们将持续不断地去发展这项技术,目的是为了降低人工介入成本,并且更快速地去响应业务的变化,从而实现更高效率地去产出。
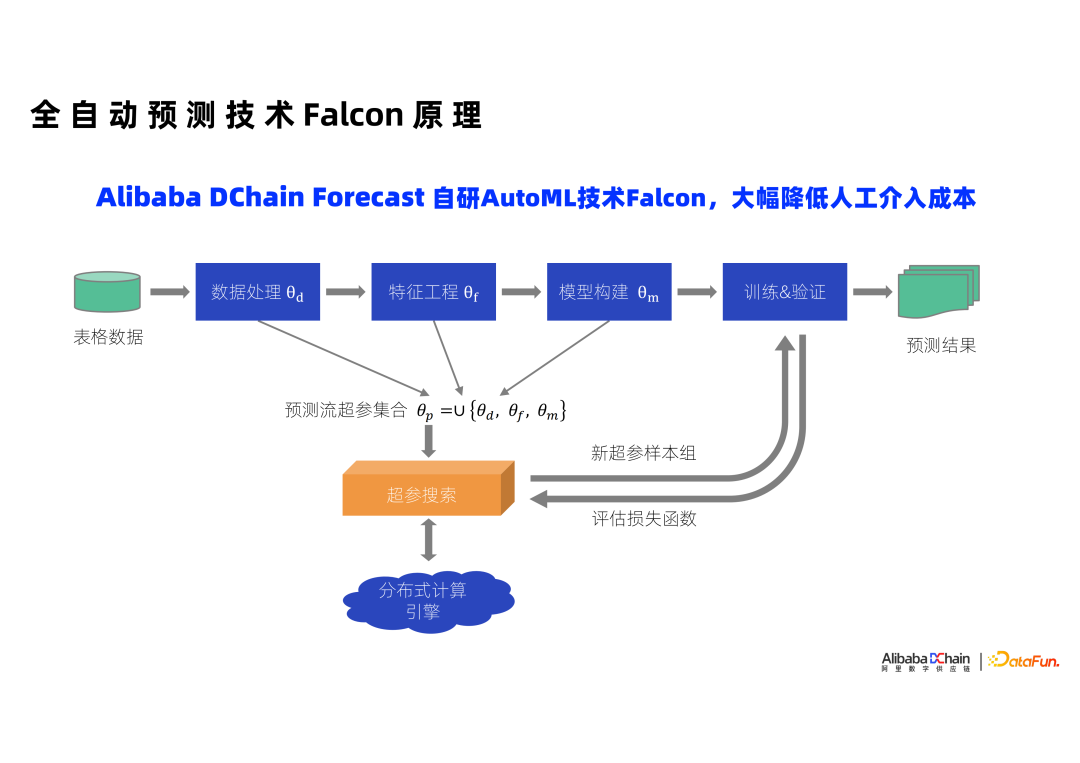
4. 使预测技术成为开箱即用的工具
在外部网站上,我们已经公开了一些 Falcon 的技术资料,核心是让预测计算流程实现自动构建和自动执行。这套自动预测流构建和执行方案在我们供应链相关的业务场景上取得了成功应用,非供应链预测场景的应用也越来越多。
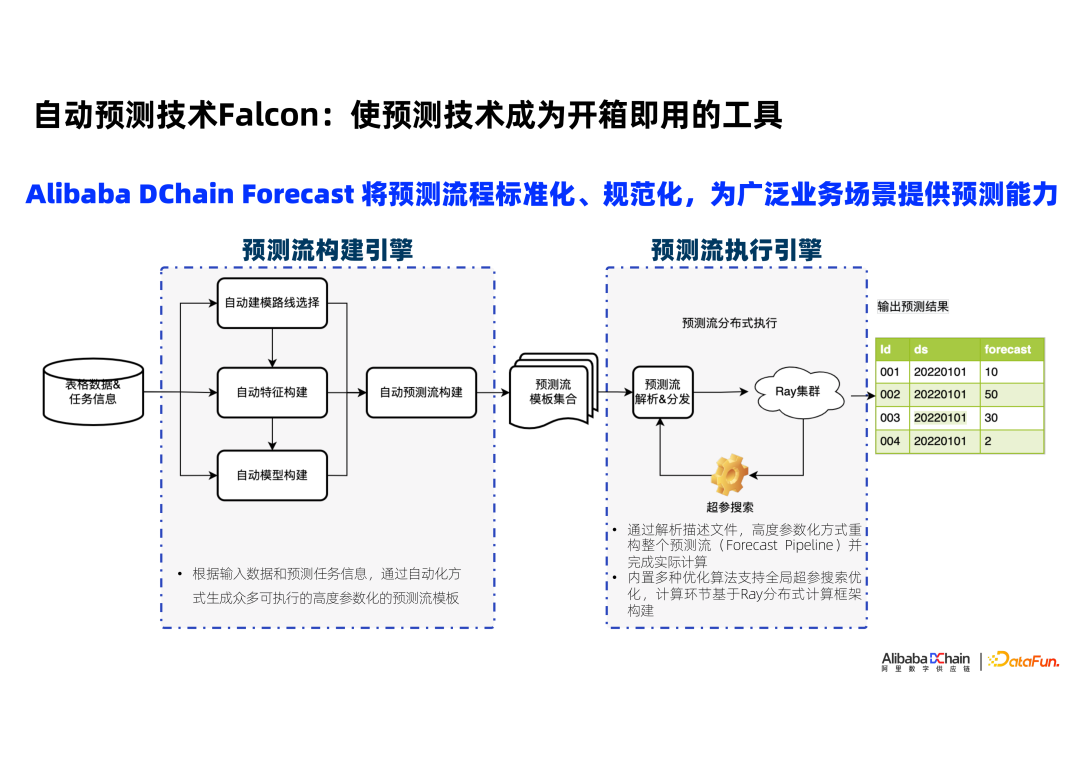
5. 自动预测技术 Falcon 的效果&先进性
对预测,大家最关注的就是准确率,为了验证 Falcon 的预测性能,我们一直在参加公开比赛。我们重点考虑它在面临通用的场景时,预测精度和稳定性能做到什么样的程度,这里列出了几项我们对外公开检验的结果。

当前的话,我们内部的 BU 也都在使用,包含一些工程人员,他可能没有预测的背景,只有工程背景,他只会调用接口,甚至他只会做一些操作,做一些数据准备,他也能来把这套体系用起来。
甚至未来可以给到我们平台的用户,希望他们可以用这样一套工具,不需要去做很多机器学习的研究,甚至技术工程上的投入,他也能来使用。
今天的分享就到这里,谢谢大家。
学习更多AI、大数据方向的技术干货,请关注公众号:DataFunTalk
下载AI、大数据方向的免费资料、行业报告,请关注公众号:DataFunSummit
可以改进初始化,也可以增加一些新的策略,可以考虑试试最新的群智能优化算法:蜣螂优化算法,亲测效果不错,新算法更容易发论文
摘要:鲸鱼优化算法(WOA)收敛速度慢,容易陷入局部最优。 针对这些问题,本文提出了一种基于多种群进化(MEWOA)的WOA变体。 首先,根据个体的适应度将个体划分为三个大小相等的子种群:探索子种群、开发子种群和适度子种群。 其次,利用不同的机制分配每个子种群的移动策略。 探索性子种群和开发性子种群分别进行全局搜索和局部搜索,而适度子种群随机搜索或开发搜索空间。 最后,我们引入了一种新的种群进化策略来帮助MEWOA提高全局寻优能力,避免局部最优。
座头鲸的捕食行为启发了WOA。它们的捕食行为包括包围猎物、泡网攻击法和寻找猎物三个阶段。
鲸鱼通过公式(4)更新自己的位置,接近最好的鲸鱼捕捉食物。
其中,t为当前迭代次数,X*(t)为最佳鲸鱼的位置向量,x(t)为位置向量需要更新的鲸鱼。A和C是系数向量,其中
和
是[0,1]之间的两个随机向量,向量A与迭代次数成正比,从2线性下降到0。
WOA的泡网攻击方法如公式(6)。
其中,D'代表当前鲸鱼与最好鲸鱼之间的距离,b通常设置为1的常数,l是[-1,1]之间的随机数。
由于鲸鱼沿着螺旋式路径游,围绕猎物呈缩小的圆圈,鲸鱼有50%的可能性选择包围猎物,50%的可能性实施泡网攻击方法。这一过程由公式(7)重新调整。
其中p是[0,1]之间的随机数。
当|a|>1时,鲸鱼选择随机移动进行全局探索,数学模型如公式(9)。
其中
是在第t次迭代时在当前种群中随机选择的鲸鱼,|A|是A的绝对值。
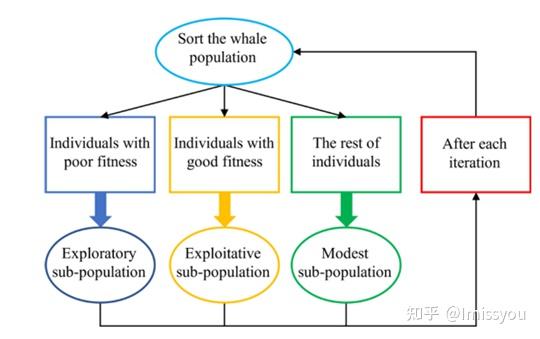
提出了一种MEWOA,根据适应度,鲸鱼种群被分为三个亚种群,每个亚种群都有相同的个体数量和不同的移动策略。
对于元启发式算法,适应度差的个体通常远离当前最优解,需要良好的全局搜索能力;具有良好适应度的个体通常聚集在当前最优解附近,并且需要较强的局部开发能力。因此,将鲸鱼种群分为三个大小相等的亚种群。具有良好适应度的个体组成开发子群体,用于加快收敛速度,快速找到全局最优解。然而,具有较差适应性的个体构成探索性子群体。由于适应度较差,搜索子种群中的个体远离当前最优解,从而使算法具有鲁棒的全局搜索能力,可以搜索问题空间的更多区域。剩余的个体组成了一个适度的亚种群,其个体适应性介于好和差之间,可以用来平衡探索和开发。在MEWOA中,每次迭代后,我们根据当前的适应度对所有个体进行重新排名。因此,每个子群体中的个体随着每次迭代而动态更新。图1是多种群划分示意图。
(1) 探索性子种群的移动策略
探索子群体中的个体由于适应度差而远离局部最优解。因此,我们让探索性子群体中的个体致力于全球探索,以探索新的区域并找到新的解决方案。因此,WOA探索子种群的移动策略采用探索阶段的公式(9)搜索。
(2) 开发子种群的迁移策略
当个体逼近当前最优解时,它会搜索其周围的区域,这种行为称为局部搜索,可以提高收敛速度和求解精度。由于开发子种群的适应度接近当前最优解,我们让开发子种群集中精力进行局部开发,以提高收敛速度和求解精度。因此,利用WOA的开发阶段实现了开发子种群的移动策略。
(3) 适度子种群的移动策略
适度子群体的适应度介于好和差之间。因此,适度子群体中的个体要么探索以找到新的解决方案,要么局部利用以增加收敛速率,从而实现探索和利用之间的随机平衡。适度的子群体的移动策略在公式(10)中给出。
(4) MEWOA的探索与开发
MEWOA是一种基于多种群机制的算法。不同的亚种群具有不同的运动策略。因此,对于MEWOA,它总是有三分之一的个体(探索性子群体)执行全局探索,三分之一的个体(开发子群体)执行局部开发。此外,三分之一的个体(适度的子种群)在探索和开发之间被随机选择。因此,对于MEWOA,它在整个迭代过程中同时具有全局探索和局部开发能力。
MEWOA的种群进化策略当所有个体的位置更新后,下一次迭代立即进行种群进化,帮助MEWOA提高种群多样性和收敛速度,消除局部最优。因此,我们指定MEWOA在t是奇数时进行位置更新,并且在t是偶数时进行群体进化;t表示当前迭代次数。因此,MEWOA执行位置更新和种群进化的概率均为50%。
(1) 探索性子种群的群体演变
探索子种群中的个体通过增加位置向量的绝对值来扩大搜索范围,以增强全局探索能力。公式(12)给出了探索性子种群的演化过程。
其中
是[1,2]之间的随机数。如果当前位置是局部最优值,则公式(12)可以帮助个体以一定的概率逃离局部最优。这是因为在公式(12)的作用下,当前位置矢量的绝对值增加,允许个体探索远离当前位置的其他区域。MEWOA可以搜索其他区域,使全局搜索能力更加强大。
(2) 开发子种群的群体演变
在剥削子群体中的个体通过围绕当前最优解执行深度局部搜索来进化其位置,见公式(14)。
是一个随机数,其价值在[0,2]之间,
是当前最优解的位置矢量。在开发子种群中个体的地位被位置矢量的增加或减少当前的最优解,从而实现搜索周围区域的当前最优解。这种进化策略可以充分利用当前最优解的位置信息来加速收敛性和提高精度。
(3) 适度子种群的群体演变
OBL常被用来提高元启发式算法的性能,它可以帮助增加种群的多样性。因此,我们让适度子种群中的个体基于OBL进化其位置,表达式如式(16)所示。
其中
是问题空间的下边界,
是上边界。
是目标函数,
是基于OBL的新位置。OBL增加了MEWOA的种群多样性,使其能够摆脱局部最优并探索新的区域。
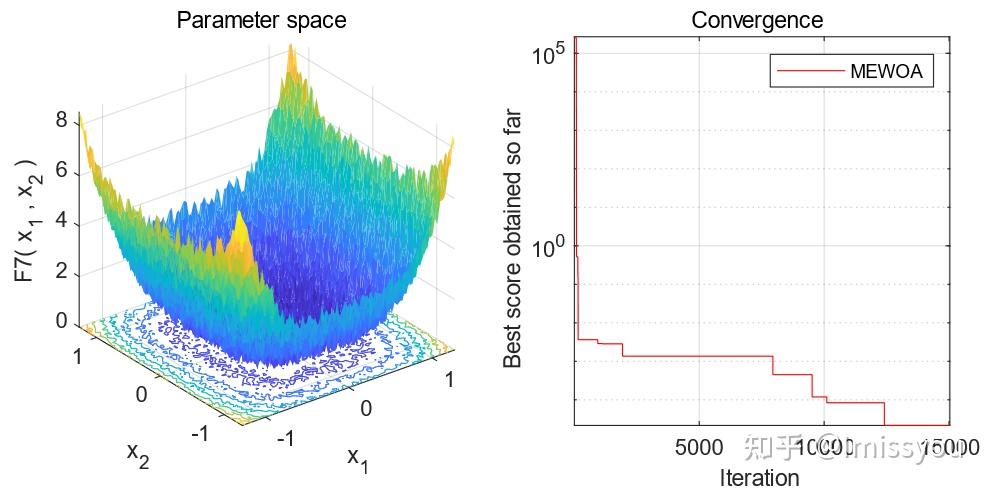
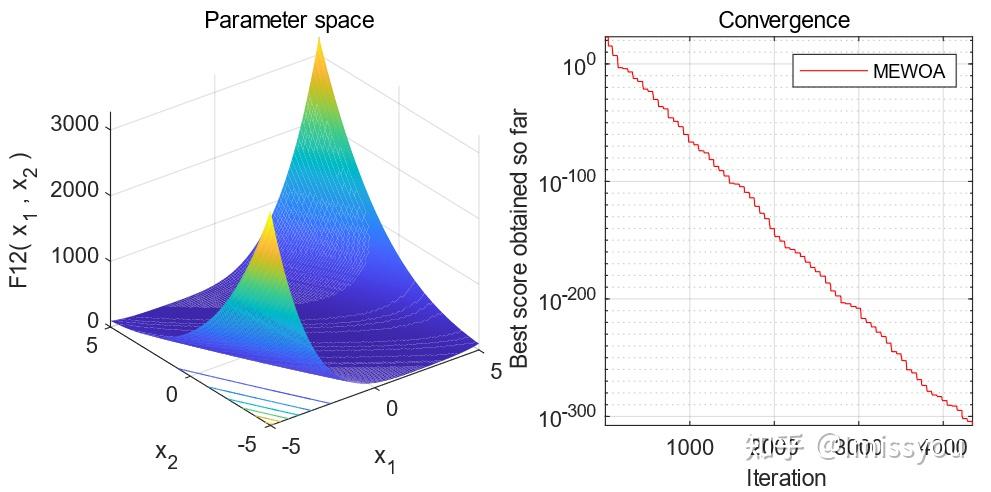
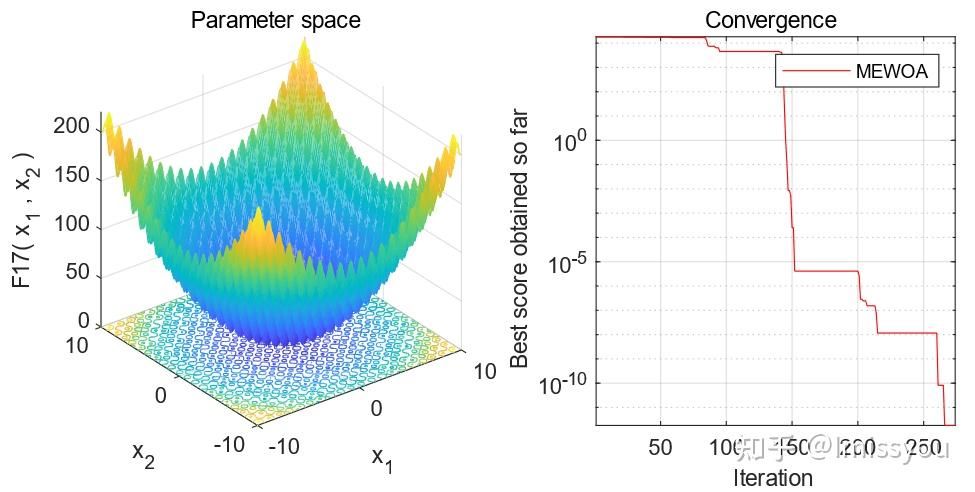


[1]Mirjalili S, Lewis A. The whale optimization algorithm[J]. Advances in engineering software, 2016, 95: 51-67.
[2]Sun Y, Chen Y. Multi-population improved whale optimization algorithm for high dimensional optimization[J]. Applied Soft Computing, 2021, 112: 107854.
[3]Zhou Y, Hao J K, Duval B. Opposition-based memetic search for the maximum diversity problem[J]. IEEE Transactions on Evolutionary Computation, 2017, 21(5): 731-745.
[4]Yuan Y, Mu X, Shao X, et al. Optimization of an auto drum fashioned brake using the elite opposition-based learning and chaotic k-best gravitational search strategy based grey wolf optimizer algorithm[J]. Applied Soft Computing, 2022, 123: 108947.
[5]Abd Elaziz M, Mirjalili S. A hyper-heuristic for improving the initial population of whale optimization algorithm[J]. Knowledge-Based Systems, 2019, 172: 42-63.
[6]Shen Y, Zhang C, Gharehchopogh F S, et al. An improved whale optimization algorithm based on multi-population evolution for global optimization and engineering design problems[J]. Expert Systems with Applications, 2023, 215: 119269.
NOTE:需要代码请私聊
本文改进主要参考:
S. Li and J. Li, "Chaotic dung beetle optimization algorithm based on adaptive t-Distribution," 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), Chongqing, China, 2023, pp. 925-933, doi: 10.1109/ICIBA56860.2023.10165106.
作者在上一篇文章中介绍了蜣螂优化算法(dung beetle optimizer,DBO),其具有收敛速度快和准确率高的特点,可以有效地解决复杂的寻优问题。然而虽然其具有比PSO、GWO等算法更好的优化性能,但其存在初始种群分布不均匀、全局探索和局部开发能力不平衡、易陷入局部最优等缺点。
因此,受混沌映射和自适应T分布的启发,提出对DBO算法进行改进。混沌映射如Logistic映射和Tent映射,能够提高初始种群在搜索空间的分布质量,加强其全局搜索能力;而自适应t分布能在迭代的不同时期提高算法的全局/局部搜索能力。两种方法相辅相成,能够帮助DBO算法获得更好的优化性能。
实验部分,本文将改进的DBO算法与DBO以及一些常用的智能算法在9个标准测试函数上进行实验对比,以验证改进的有效性。
00 文章目录
1 蜣螂优化算法原理
2 自适应混沌蜣螂优化算法
3 代码目录
4 实验结果
5 源码获取
01 蜣螂优化算法原理
关于蜣螂算法原理作者在上一篇文章中已经作了介绍,感兴趣的朋友可以点下面的链接查看。
02 自适应混沌蜣螂(Adaptive Chaos DBO,AC-DBO)优化算法
2.1 改进的Tent混沌映射
与其他群智能算法一样,原始DBO在求解复杂问题时,通过随机生成位置的方法初始化种群的个体位置,会导致种群的多样性低,对问题进行寻优的收敛速度比较慢。为了能够让个体在算法开始时有较高的全局搜索能力,需要让种群的位置均匀分布在整个问题的解空间内,因此使用混沌算子对种群进行初始化。
混沌作为一种非线性的自然现象,以其混沌序列具有遍历性、随机性等优点,被广泛用于优化搜索问题。利用混沌变量搜索显然比无序随机搜索具有更大的优越性[1]。
目前文献中常用的混沌扰动方程有Logistic映射和Tent映射等。Logistic映射在作者前面的文章中介绍过,由文献[2]可知Logistic映射的分布特点是:中间取值概率比较均匀,但在两端概率特别高,因此当全局最优点不在设计变量空间的两端时,对寻找最优点是不利的。而Tent混沌映射具有比Logistic混沌映射更好的遍历均匀性和更快的搜索速度。下图中展示了Logistic和Tent的混沌序列:
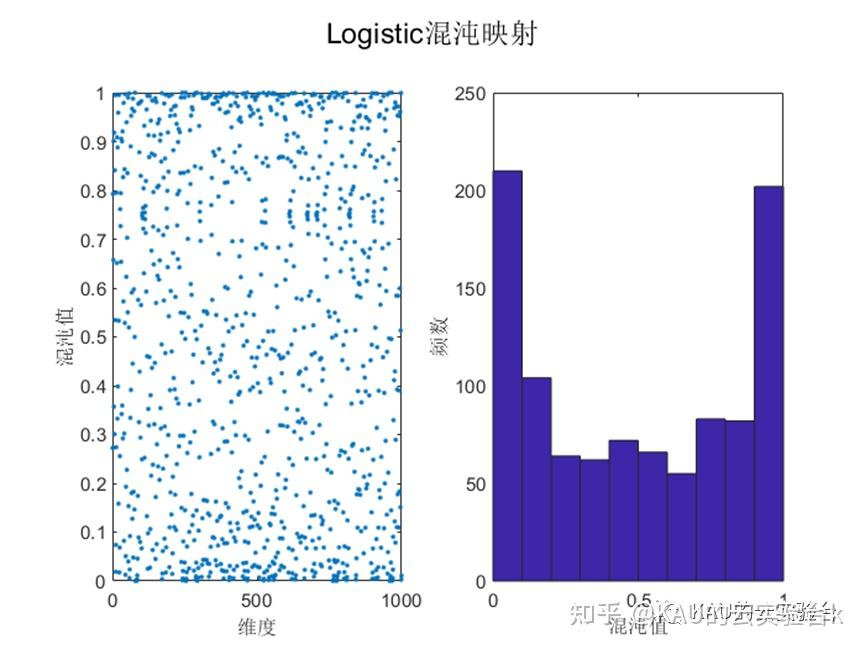
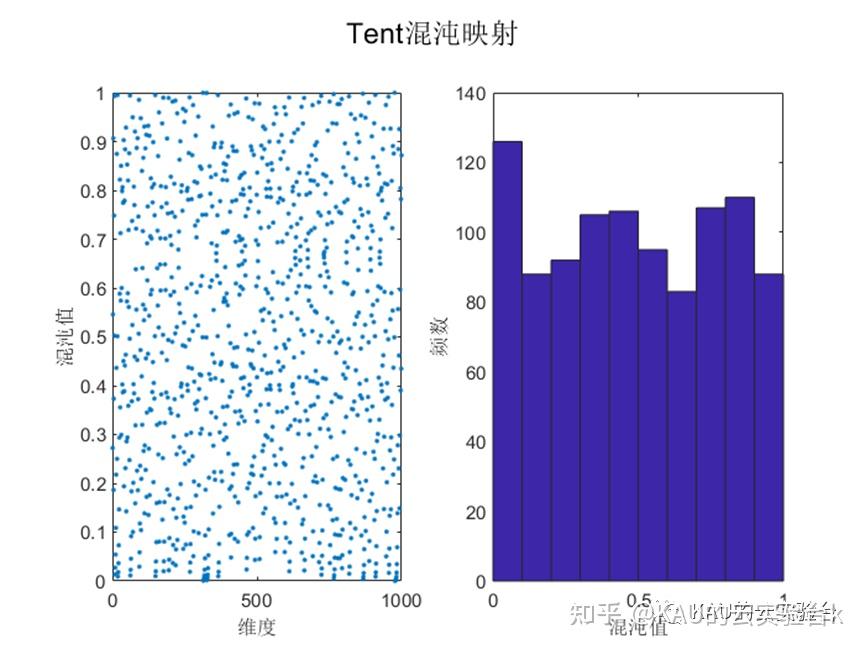
可以看到,Logistic混沌映射在边界区域取值概率明显更高,而Tent在可行域的取值概率更为均匀,因此若将Logistic混沌映射用于初始化种群时,其混沌序列的不均匀性会影响算法寻优的速度和精度。因此本文利用Tent的遍历性产生更为均匀分布的混沌序列,减少初始值对算法优化的影响。
Tent混沌映射的表达式如下:
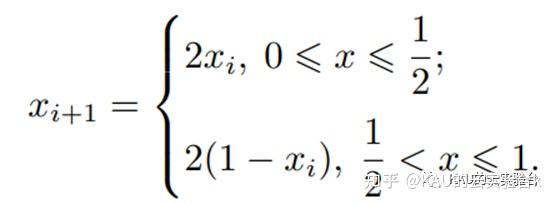
分析Tent混沌迭代序列能够发现序列中存在小周期,并且存在不稳周期点. 为避免Tent混沌序列在迭代时落入小周期点和不稳定周期点,在原有的Tent 混沌映射表达式上引入一个随机变量rand(0, 1) /N ,则改进后的Tent混沌映射表达式如下[3]:
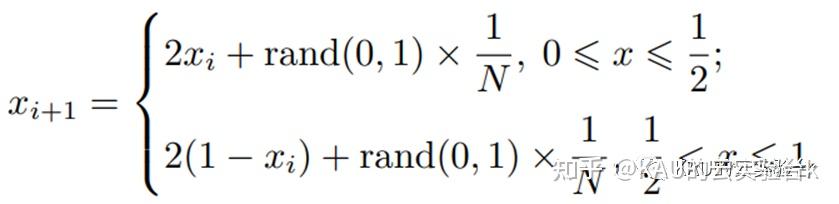
其中: N 是序列内粒子的个数。引入随机变量rand(0, 1) /N 不仅仍然保持了Tent混沌映射的随机性、遍历性、规律性,而且能够有效避免迭代落入小周期点和不稳定周期点内。本文算法引入的随机变量,既保持了随机性, 又将随机值控制在一定的范围之内,保证了Tent混沌 的规律性.根据Tent混沌映射的特性。改进的Tent混沌序列效果如下:
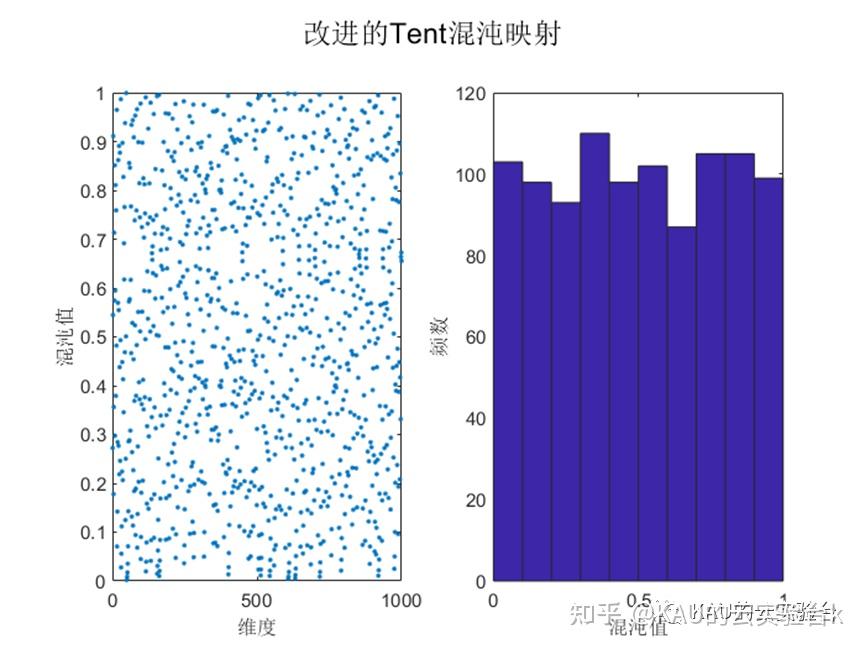
由图可知,改进后的Tent混沌映射其均匀性得到了提高,因此本文以改进Tent混沌性来代替蜣螂优化算法的随机初始化,以提高和改善初始种群在搜索空间上的分布质量,加强其全局搜索能力,从而提高算法求解精度。
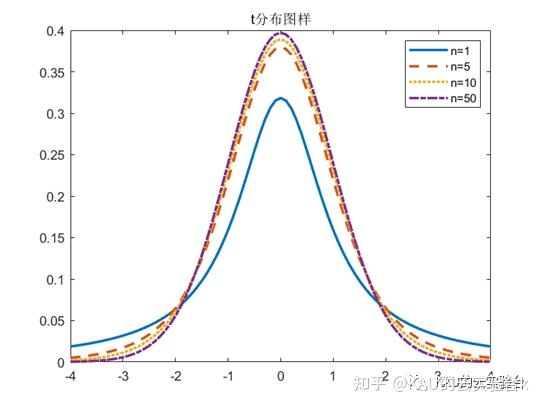
2.2 自适应t分布
t分布也叫学生t分布,包含自由度参数n。n的值决定t分布曲线的形状,n值越小,则曲线越平坦,n值越大,则曲线越陡峭。
t分布的概率密度函数为:
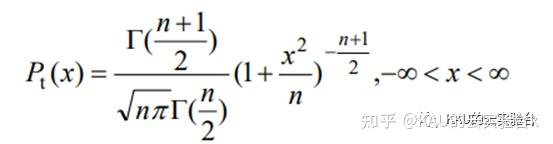
式中,t为自由度参数,x 为扰动力度,Γ( )为伽玛函数。当t(n→∞)→N(0,1)时,t(n→1)=C(0,1),N(0,1)为高斯分布,C(0,1)为柯西分布。高斯分布和柯西分布是t分布的两种边界特例[4],它们的函数分布如图2所示。
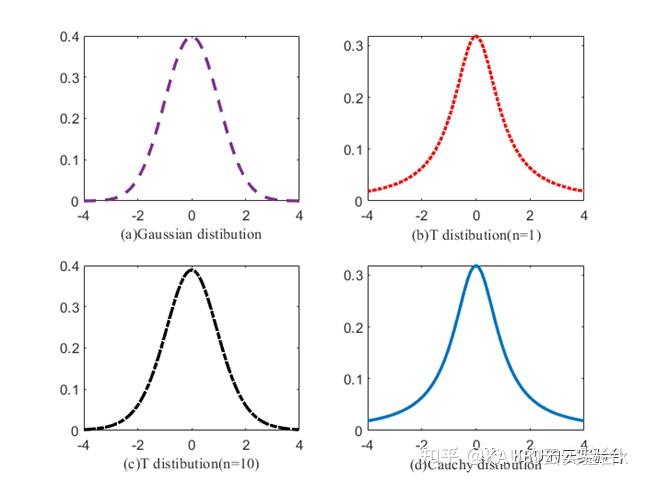
当算子发生柯西突变时,算法的全局搜索性能较好,种群多样性较高。当算子发生高斯突变时,算法收敛速度更快,局部寻优能力更强。
t分布结合了柯西分布和高斯分布的优点,在自由度参数n从1→∞的过程中,可以通过t分布突变算子来平衡和提高算法的全局/局部搜索能力。因此,本文采用自由度参数n=iter的t分布来优化个体的搜索方向和距离,步长会随着迭代次数的增加而自适应变化。采用自适应t分布突变策略对蜣螂位置进行扰动的方程如下:
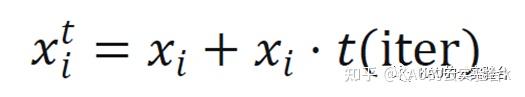
式中,xti为突变后的蜣螂位置,xi为第i只蜣螂个体位置,t(iter)为以迭代次数iter为自由度的t分布。
在迭代开始时,t分布突变类似柯西突变,此时算法具有良好的全局探索能力,增加了种群的多样性,且跳出局部最优的能力也增强了。随着迭代次数的增加,t分布突变近似于高斯突变,提高了算法的局部开发能力,其对于整个种群的扰动力度也从强到弱转化。通过引入自适应t分布突变作为一种改进的搜索策略,能够有效增强算法的优化性能,有利于提高算法逃避局部最优的能力。
通过自适应t分布突变扰动策略虽然能增强算法全局搜索和跳出局部最优的能力,但是没法确定扰动之后得到的新位置一定比原位置的适应度值要好,因此在进行变异扰动更新后,加入贪婪规则,通过比较新旧两个位置的适应度值,确定是否要更新位置。
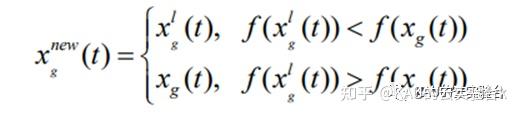
其中, xnewg(t)为经过贪婪规则更新后的个体位置,xlg(t)为扰动后的个体,xg(t)为扰动前的个体, f ()代表粒子适应度函数。
2.3 自适应混沌蜣螂优化算法步骤
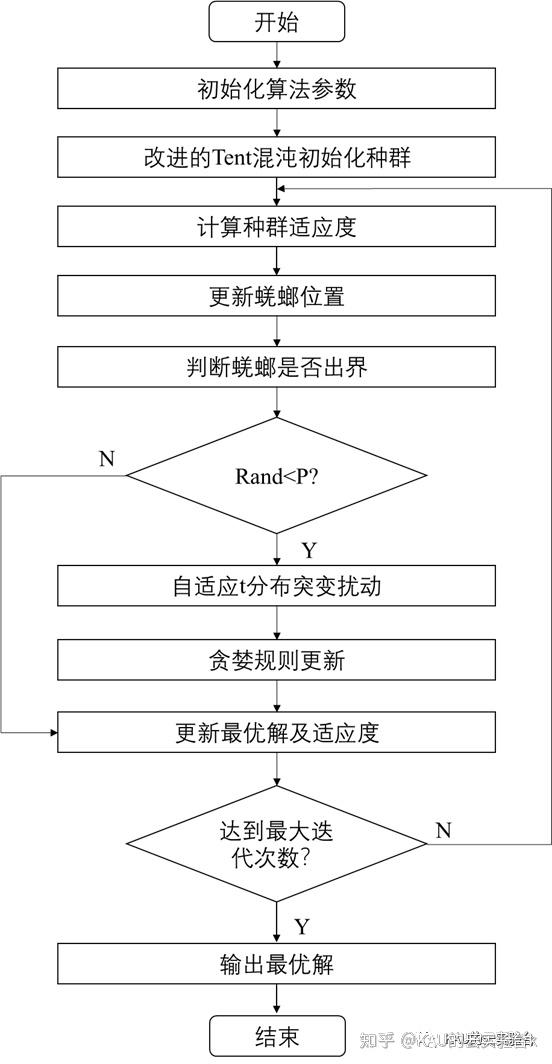
综上所述,自适应混沌蜣螂优化算法主要分为六个步骤。
1)初始化种群大小,迭代次数,t分布概率等参数
2)使用改进的Tent混沌映射初始化蜣螂种群
3)根据目标函数计算所有蜣螂位置的适度值;
4)更新所有蜣螂的位置;
5)判断每个更新后的蜣螂是否出了边界;
6)若随机数rand小于给定P值,则根据t分布突变策略进行扰动,产生新解
7)根据贪婪规则确定是否更新
8)更新当前最优解及其适度值;
9)重复上述步骤,在 达到最大迭代次数后,输出全局最优值及其最优解。
流程图如下:
03 代码目录
代码注释完整,其中部分程序如下:

代码注释完整,其中部分程序如下:
04 实验结果
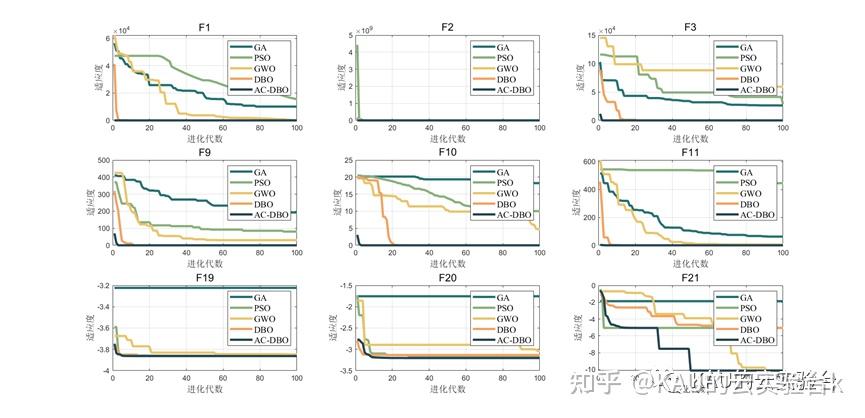
在本节中,通过单峰,多峰,固定多峰共9个经典测试函数验证AC-DBO的搜索性能,通过仅具有一个全局最优值的单峰函数来测试算法的局部搜索能力,并使用多峰函数来评估全局搜索能力。将改进的蜣螂优化算法与另4种被广泛研究的优化算法(PSO、GA、GWO、DBO)进行比较。
为保证实验公平性,所有算法的迭代次数与种群数都设置为100。
单峰函数采用F1,F2,F3。多峰函数采用F9,F10,F11。固定多峰函数采用F19,F20,F21。部分函数样图如下:
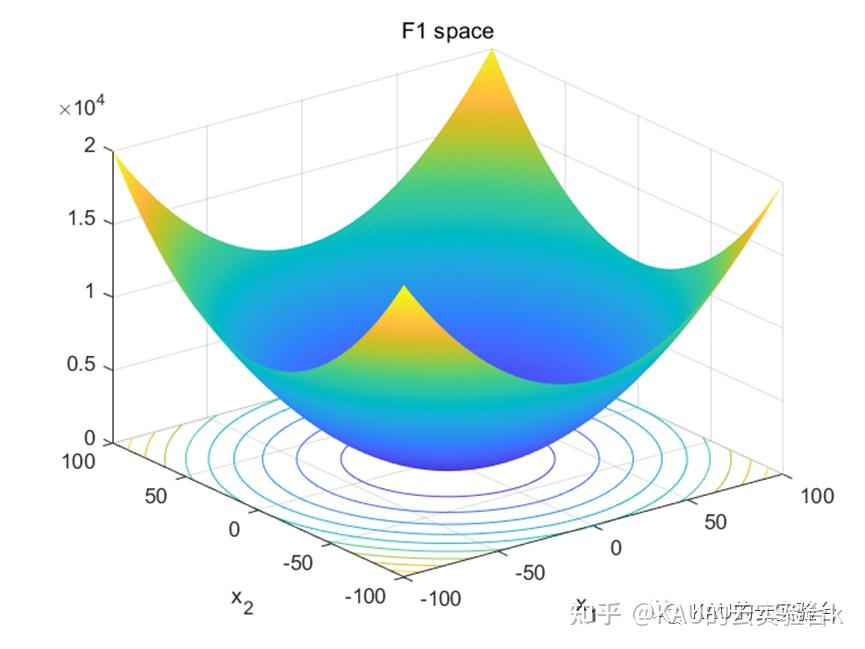
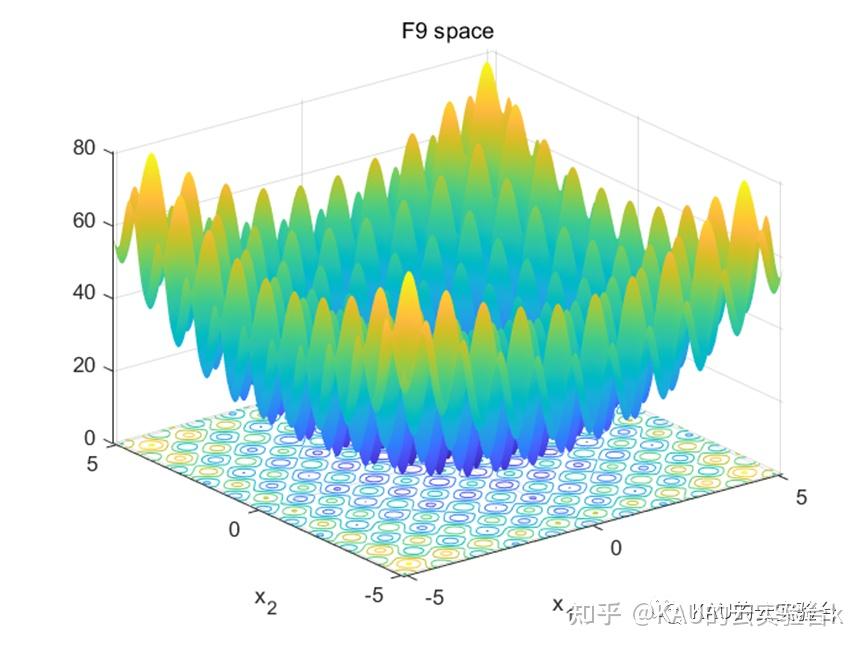
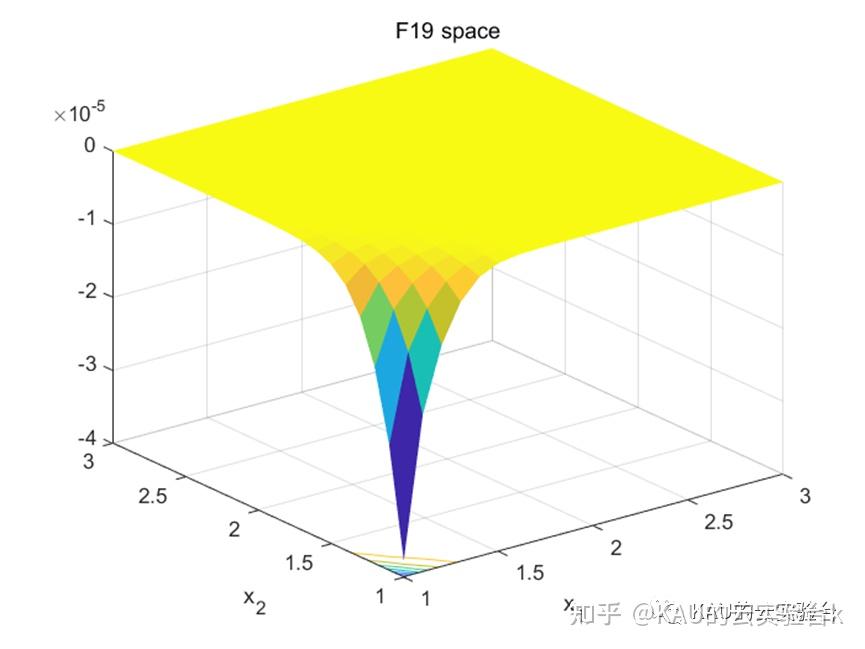
利用上述的5种优化算法对共计9种测试函数进行寻优,结果如下:
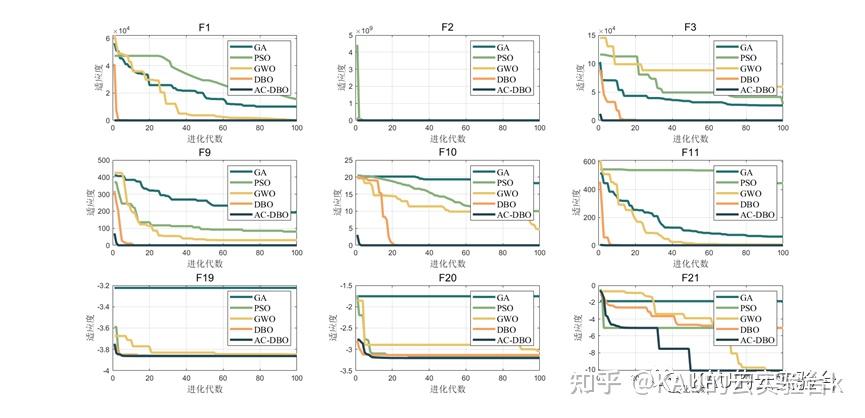
由图可以看出,改进后的算法在搜索精度以及收敛速度上皆优于其他算法,其性能得到了显著提高。
05 源码获取
见个人简介
参考文献
[1]张云鹏,左飞,翟正军.基于双Logistic变参数和Cheby-chev混沌映射的彩色图像密码算法[J.西北工业大学学报, 2010,28(4): 628-632.
[2]江善和,王其申,汪巨浪.一种新型SkewTent映射的混沌混合优化算法[J.控制理论与应用, 2007,24(2): 269-273.
[3]张娜,赵泽丹,包晓安,等.基于改进的Tent混沌万有引力搜索算法[J].控制与决策,2020,35(4):893-900.
[4]Fangjun Zhou , Xiangjun Wang , Min Zhang . Evolutionary Programming Using Mutations Based on the t Probability Distribution[J].2008.36(4):667-671.
另:如果有伙伴有待解决的优化问题(各种领域都可),可以发我,我会选择性的更新利用优化算法解决这些问题的文章。
如果这篇文章对你有帮助或启发,可以点击右下角的赞/在看(?_)?(不点也行)
今天为大家带来一期四种策略改进的哈里斯鹰算法代码与原理讲解,方便大家改进自己的算法~学会这一篇可扩展到所有算法!首先介绍一下原始哈里斯鹰算法!
由于原始算法文章众多,因此这里为了方便直接贴图~哈里斯鹰算法是2019年受哈里斯鹰捕食兔子过程启发而提出的优化算法,具有全局搜索能力强,需要调节的参数较少等优点。



废话不多说,直接来看一下是如何改进的!
废话不多说,直接来看一下是如何改进的!
这个改进点还是比较传统的,也能够在很多改进的文章中看到,关键在于你怎么用,用在哪里。那么在这里,反向学习主要在初始化阶段生成解的“对立”局部,以覆盖可行域中的大面积,从而提高初始解的多样性。即使没有先验知识,使用OBL仍然可以获得更合适的起始候选者,并提高检测到更好区域的概率。具体的公式为:
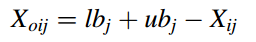
其中,j=1,2,…,D(特定问题的维度),i=1,2,..,N(哈里斯鹰的总数)。此外,在相反解的计算中使用了上值ubj和下值lbj。
大多数改进策略通常将混沌映射放在初始化中,然而初始化在整体改进策略里效果并不明显。在这里,使用逻辑混沌映射序列来调整HHO的随机参数r,用混沌映射序列代替随机参数。其中的优势就在于,由于遍历性和非重复性的特点,混沌映射可以比依赖于概率的随机遍历搜索更高的速度执行整体搜索,有助于控制开发机制。公式如下所示:
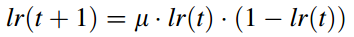
其中,t表示当前迭代次数。此外,控制参数l=4,lr(1)属于(0,1)且lr(1)不等于0.25,0.5,0.75,1。与HHO不同,r取自混沌序列lr,并且以这种方式r(t)=lr(t)。
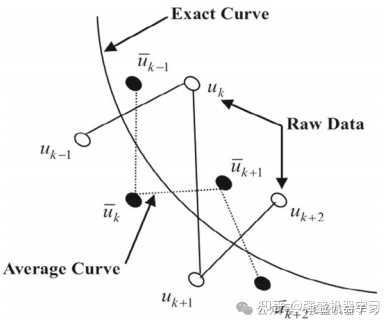
为了减少或避免最优解中的控制函数波动和角点,在改进的HHO的处理阶段嵌入了平滑技术来平滑解。由下图可知,白色点是平滑前的控制值,而黑色点是相应的平滑值。但是要注意,平滑技术仅在原始数据中出现Z字形时执行,并且出现如u(k-1)、uk和u(k+1)之间。采用基于三个连续点中的每一个的平均值来减小跳跃的幅度。k是权重系数,并且用于在点k处进行平滑的公式可以表示为:

其中左边带上箭头的uk是uk的平滑值,并在接下来的迭代步骤中替换它。
这个策略还是非常新颖的,知网基本没什么人用过,大家可以将这个策略加入到其他算法!
为了利用当前最佳个体种群信息,加快搜索速度,降低陷入局部最优的风险。采用最著名的DE/current-to-best/1突变算子来代替方程中的原始位置更新策略。原始算法的公式(7)可改写为:
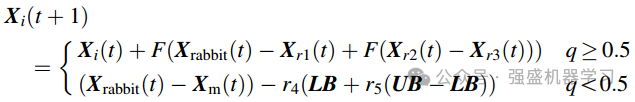
其中r4和r5也是(0,1)内的随机数。
一旦全局搜索阶段过去,就应该缩小搜索空间,加强开发强度,从而有利于收敛到全局最优。Levy变异算子由于其重尾分布,可以产生不同的后代,并可以帮助个体轻松逃离局部最优。
因此,使用局部Levy突变代替全局Levy飞行。原始算法的公式(8)和(11)可以重写为:
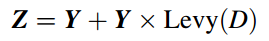
实际上,这里采用了差分进化算法和莱维分布的思想,最大程度上保留差分进化和莱维飞行的优点。通过两种变异混合进一步提高算法搜索能力,这个策略还是非常有效的,这一点也可以扩展到其他算法!
为了方便大家比较,这里采用经典的23个标准测试函数,也就是CEC2005与原始哈里斯鹰算法进行对比~

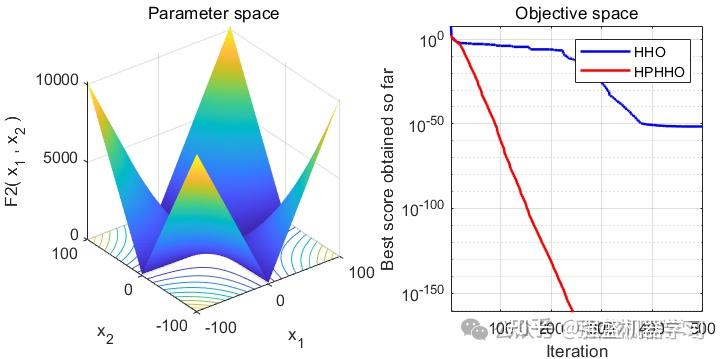
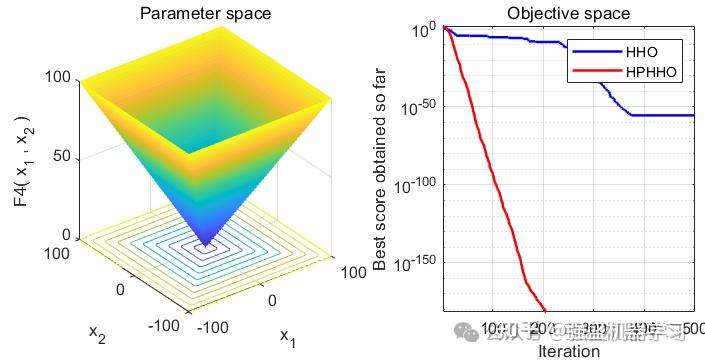
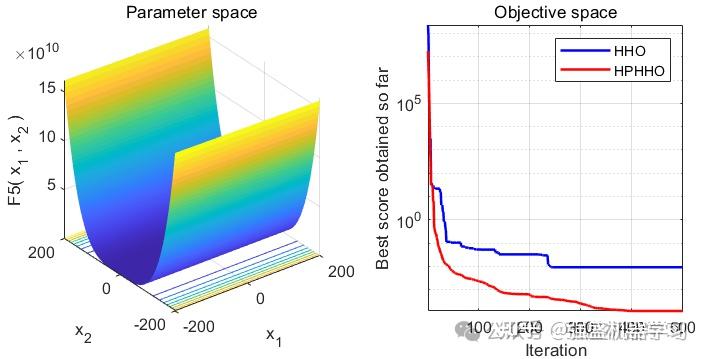
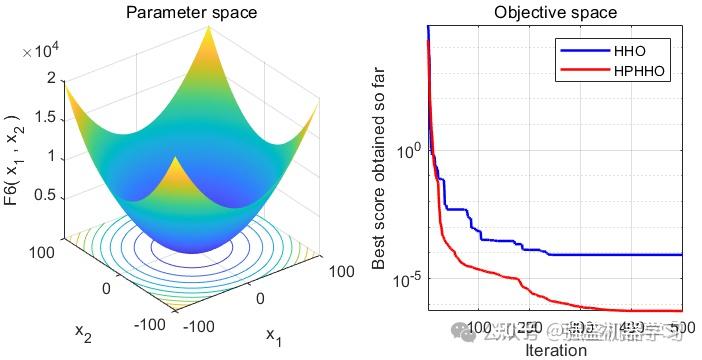
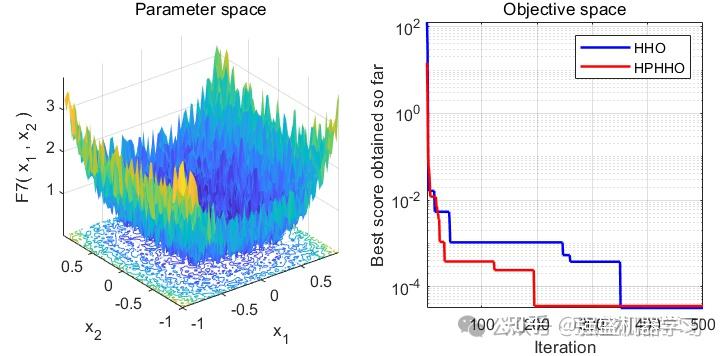
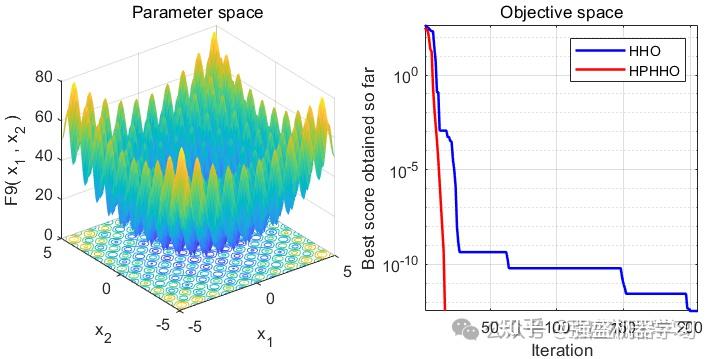
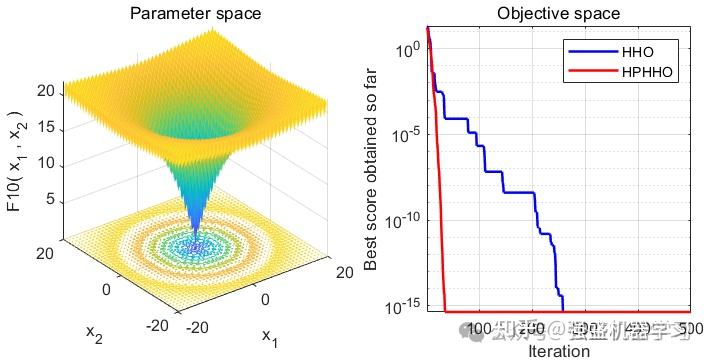
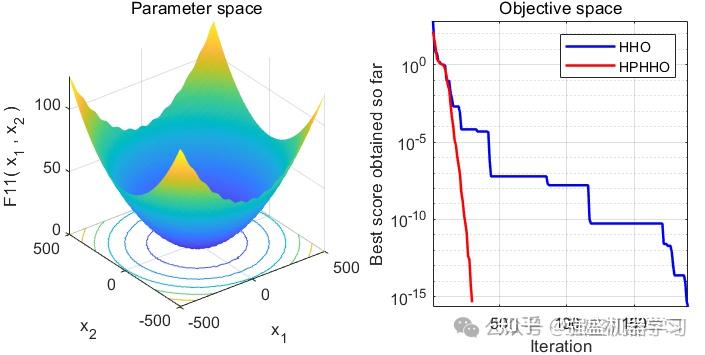
可以看到,改进后的HHO算法效果还是非常不错的!在大部分测试函数上都非常有效!大家可以用它来试试优化SVM、LSTM等各种应用场景~
如果需要获得图中的完整测试代码,可查看链接:
创新性不足?四种策略改进的哈里斯鹰算法!学会这一篇可扩展到所有算法!
也可后台回复个人需求定制本文改进HHO算法优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、ESN等等均可~
2.组合预测类:CNN-SVM、CNN-LSTM/BiLSTM/GRU/BiGRU-Attention、Adaboost类、DBN-SVM等均可~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、CEEMDAN、ICEEMDAN、SVMD等分解模型均可~
4.其他:机器人路径规划、无人机三维路径规划、DBSCAN聚类、VRPTW路径优化、微电网优化、无线传感器覆盖优化、故障诊断等等均可~
5.原创改进优化算法(适合需要创新的同学):2024年的NRBO、CPO、PO、WOA等任意优化算法均可,保证测试函数效果!
更多代码链接:
?# Movielens数据集+WEB+Canopy聚类+Kmeans聚类+协同过滤推荐+测评指标MAE实现
1、使用movielens数据集(943个用户,1682部电影,80000条评分数据); 2、输入用户id(1-943); 3、创建用户-电影评分矩阵; 4、canopy聚类算法根据用户评分对用户聚类; 5、将canopy聚类结果作为kmeans聚类初始点,进行kmeans聚类; 6、根据聚类结果进行协同过滤推荐; 7、计算推荐算法测评指标mae值; 8、本文描述项目实现详细过程看上一篇博客Movielens数据集+Canopy聚类+Kmeans聚类+协同过滤推荐+测评指标MAE 基于用户的协同过滤推荐算法 聚类算法 代码实现 程序实现
1、项目目录

1、首页
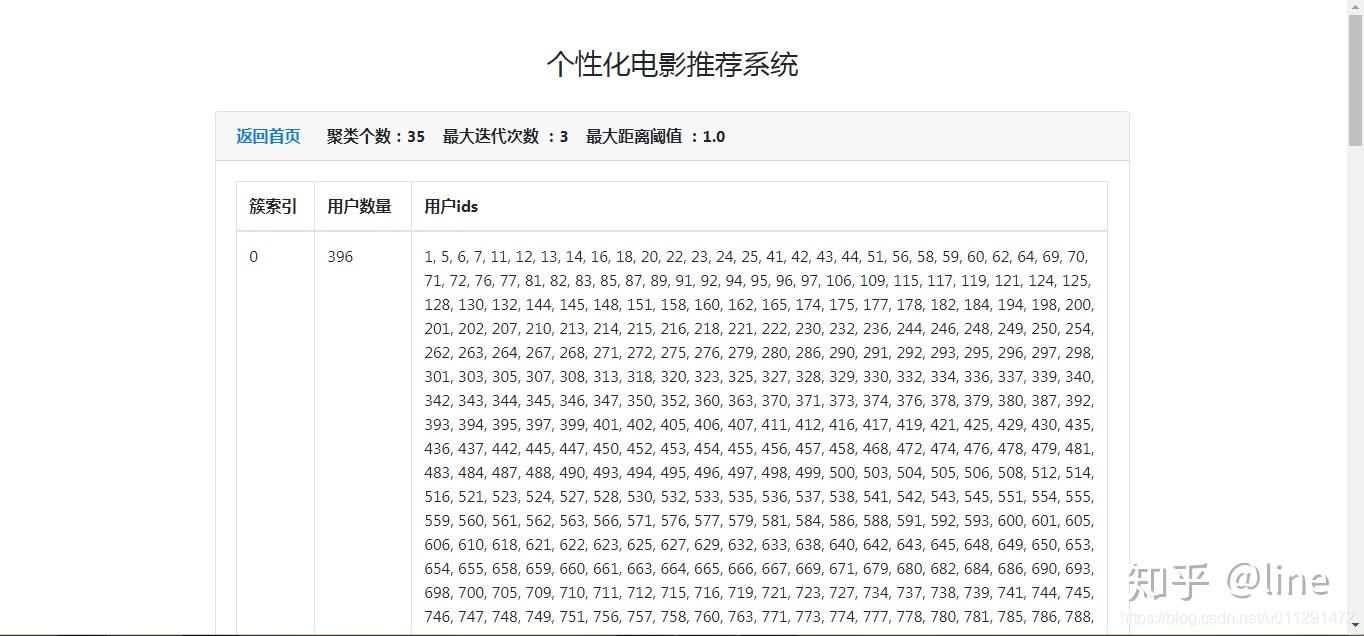
2、Canopy+Kmeans聚类结果

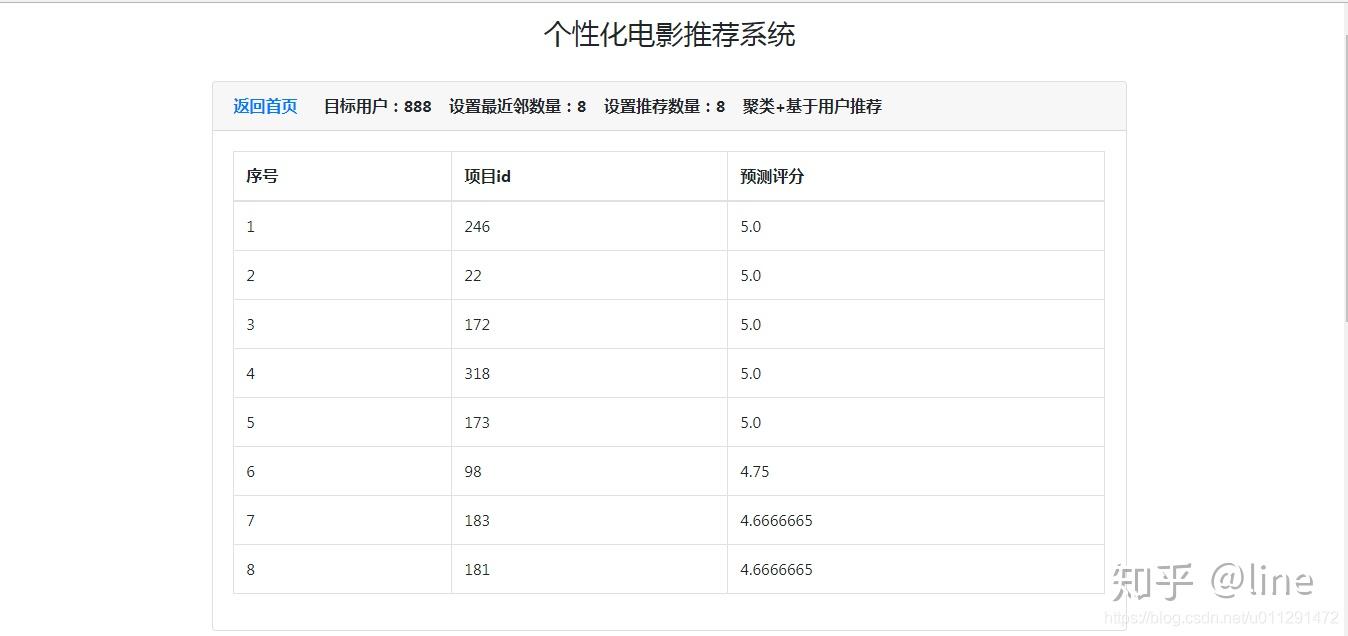
3、协同过滤推荐算法结果
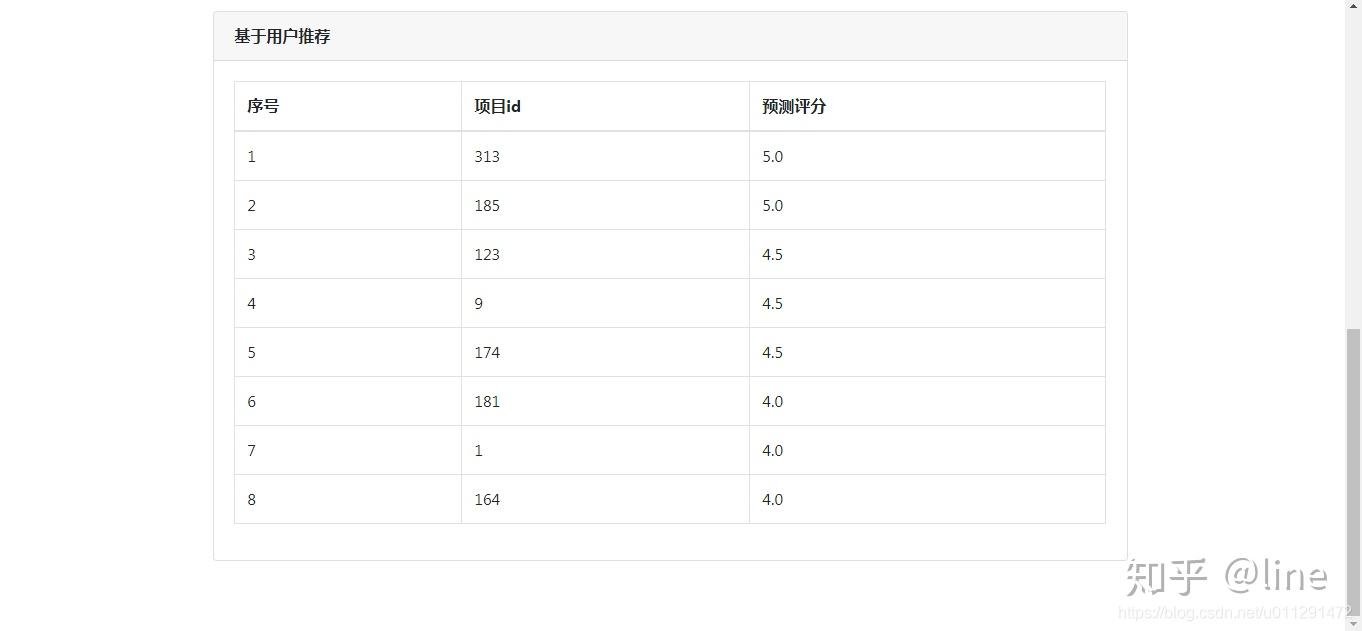
4、推荐算法测评指标MAE+RECALL+PRECISION
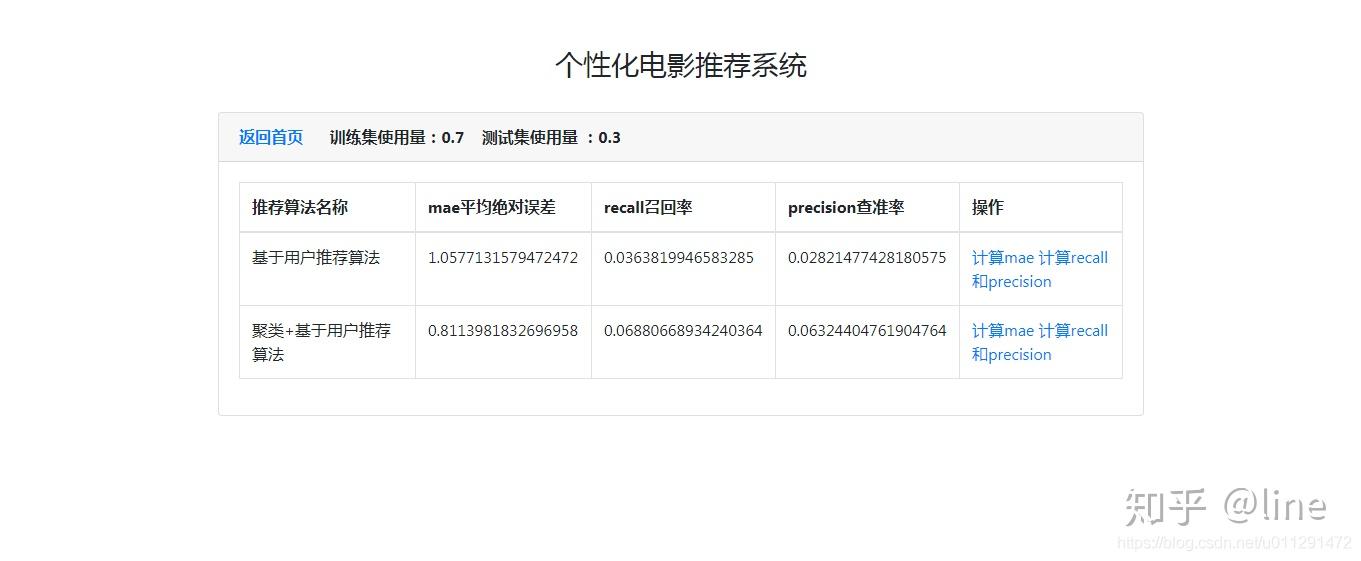
作者专业长期研究各种协同过滤推荐算法,欢迎留言、私信互相交流学习,后续会不断更新不同的协同过滤推荐算法,欢迎关注。扣511873822
CS 算法已在工程设计、多目标优化问题、测试数据自动生成、参数估算及连续函数优化问题等方面得到应用。但是要进一步完善CS算法的收敛速度和解的质量,包括步长改进、参数自适应、以及其他算法混合。
这篇论文通过Potter 和 de Jong提出求解函数优化问题的合作协同进化( Cooperative Co-Evolutionary,CC) 通用框架,将 CS 算法作为框架的子组件,提出合作协同进化的布谷鸟搜索算法( Cooperative Co-evolutionary Cuckoo Search,Co2CS), 以改善 CS 算法求解连续函数优化问题的性能。
关键点:合作协同进化
合作协同进化的布谷鸟搜索算法:
合作协同进化为演化算法求解高维或复杂的优化问题提供通用框架,其采用“分而治之”策略

本文实验结果分析:
对于具有变换特点的函数而言,Co2CS 算法的平均误差明显优于 CS 算法;对于变换且旋转的函数而言,Co2CS 算法的平均误差基本上都是明显优于CS 算法。
Co2CS 算法有较快的收敛速度,Co2CS 算法收敛于指定误差阈值所需的平均函数评价次数优于CS 算法,体现出在迭代早期具有较快的收敛速度。后期的收敛情况Co2CS 算法具有更优的平均误差。
函数变量间独立时,使得Co2CS 算法充分利用子群体的独立进化引导整个群体进行,加快收敛速度,并获得较优的平均误差。但是函数最优解分别在边界和边界之外且函数的变量间是相关联时,使得各子群体较难独立进化,Co2CS 算法的性能就会下降。
当变量间是对立时,随着子群体数目增加,Co2CS 算法的性能得到进一步改善,在最大子群体数目时收敛于全局最优。当函数的变量间是相关联时,Co2CS 算法随着子群体数目增加,其性能进一步恶化。子群体数目增加将进一步破坏其关联性,不利于函数的优化。(对变量独立的函数而言,Co2CS 算法能较好地利用子群体的进化与合作引导整个群体的进化; 对变量相关联的函数而言,较少的子群体数目仍保留变量间的关联性,Co2CS算法也能较好地利用子群体进化与合作引导整个群体的进化。)
由于 Co2CS 算法将问题分解成子问题,需要额外存储空间,同时在空间操作及问题分解与合并上将消耗一定时间,导致 Co2CS 算法的时间复杂度和空间复杂度都较CS 高。
总结:
论文从运行时间角度度量算法的复杂度,后续的工作将从理论上分析算法的复杂度。另外,如何提高变量间高度关联函数的性能,值得进一步研究。
这篇文章,改进算法利用解与当前最优解之间对应维上距离,实现随机游动步长的自适应调整。距离当前最优解对应维越远,维的随机游动步长越长,反之越短。利用解的适应度与群体平均适应度的关系自适应调整发现概率,使劣质解比优秀解更容易被淘汰。
作为一种新兴的群体智能算法,CS算法存在后期搜索精度不高、收敛速度缓慢等缺点。无论 是采用 Levy飞行随机游动还是偏好随机游动生成的新解,都采用统一标准更新解的每一维。对于多维目标,由于存在维间互扰现象,统一更新每一维将影响算法的收敛速度和解的质量,难以体现每一维与最优解的关系,不利于协调算法全局搜索和局部搜索的平衡。基于此这篇文章提出一种自适应的布谷鸟搜索算法(self-adaptive Cuckoo search algorithm, ACS)。
1.自适应随机游动步长
CS算法求解连续函数优化问题时,对于函数的任意一维d,Levy飞行随机游动操作可表示为:
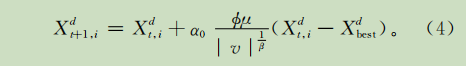
在搜索时,步长越大,越方便全局搜索,但搜索精度降低;步长越小,搜索精度越高,但是搜索的效率降低了。所以Levy飞行随机游动产生的步长虽然具有随机性,但是缺乏针对性。对此本文引入了鸟巢 和
第d维的距离定义:
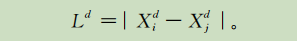
结合式子(4),生成的新解的第d维可表示为:
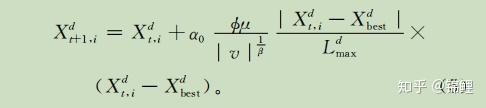
表示在第d 维上,当前最优解与其余解在相同维上距离的最大值。
2.自适应发现概率
在求解连续函数优化问题时,对于函数的任意一维d,偏好随机游动操作可表示为:
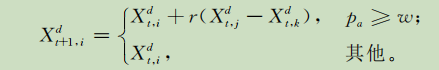
对于 ,如果过小,就不容易产生新的个体,如果过大,那么CS算法就变成纯随机搜索算法。
的选择影响算法的收敛性,标准的CS算法中
是固定的,降低了算法的收敛性能。文章中采用动态自适应机制调整参数
:
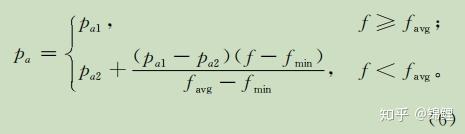
和
为(0,1)的参数,
>
。由式(6),当解的适应度大于平均适应度时,设定较大的发现概率
,使得该解容易被淘汰;而当解与最优解越接近时,设定越小的发现概率
,使得该解更有可能被保留到下一代。
总结:
总的来说,这篇文章对步长和被发现概率做出了优化,使CS算法的收敛精度和收敛速度得到提升。最后提出进一步需要研究的问题:改进算法对于不可分、低维函数的求精能力需要进一步研究。同时,自适应发现概率的上下限参数如何设置,需要进一步研究。
学生找我说看不大懂近端梯度下降算法,觉得有必要整理下。
由于本人之前也没关注过该算法,在网上找了几篇文章看了看,作者们写的核心思想基本都是一样的,但是多多少少有点小的笔误,容易引起初学者的误解,故这里再总结如下:
- 问题描述(Problem Formulation)
近端梯度下降法主要用于解决目标函数中既存在可微函数,又有不可微函数的情况,如下:
(1)
即:找到一个 使得目标函数
最小,其中
是可微函数且为凸函数,
是凸函数但不一定可微。
2. 近端算子(Proximal Operator)
近端算子定义如下:
(2)
即找到一个 使得
最小,也即找到一个
使得
尽可能小,同时
与
尽可能接近。
注:上述近端算子(2)中不含函数 ,而只与不可微函数
有关。因此我们很容易想到,先对目标函数
采用梯度下降寻找最优点
,然后采用近端算子(2)求取
,这样就得到了整个目标函数
的最优值。
3. 近端梯度下降(proximal gradient descent)
根据上面的分析,我们给出近端梯度下降算法如下:
(3)
其中, 是梯度下降的步长,
即对目标函数
进行了梯度下降从而得到了
,
则进一步考虑了目标函数
,从而得到了
,如此迭代下去,直到得到期望的最优值
。
以上即为近端梯度下降算法的思想。
- computational intelligence (CI);CI包括人工神经网络artifificial neural networks(ANN),进化计算evolutionary computation(EC)和群体智能swarm intelligence(SI)等多种形式。
- evolutionary algorithms(EAs)包括遗传算法(GA),进化策略(ES),遗传规划(GP),基于群体的增量学习(PBIL),基于生物地理的优化器(BBO)和差分进化(DE)等。
- 群智能(SI)是CI的另一种形式,用于解决优化问题。SI算法模拟和模仿自然群体或社区或系统.SI算法包括蚁群优化算法(ACO)、粒子群优化算法(PSO)、布谷鸟搜索算法(CS)、灰狼优化(GWO)等。
- GWO的理论方面:
更新机制(Updating mechanism):
(1)
(2) ,其中
是非线性调制指数(0,3).
(3) ,其中
为加入与个体适应度成比 例的步长 .
杂交版本( Hybridized versions of GWO):
(1)Kamboj提出了一种基于GWO和PSO算法的单区域单元组合问题.
(2)GWO与DE混合.
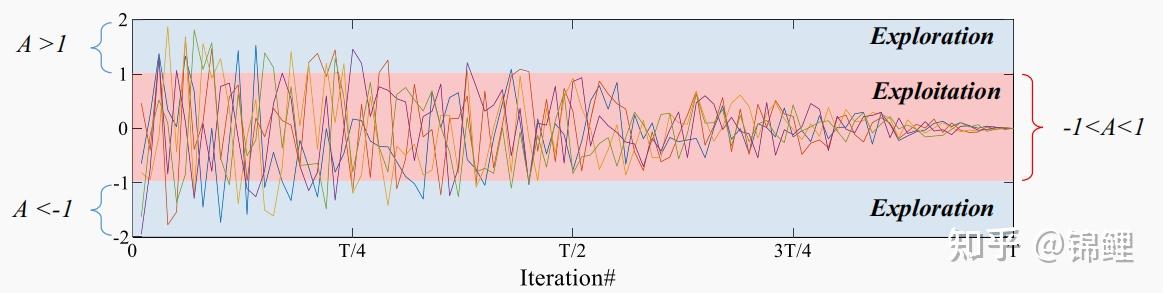
5.这张图显示了原始GWO算法中参数A的5个折线图。可以看出,虽然这个参数是随机的,但是结果,在迭代的前半部分进行探索,然后在后半部分进行开发。
6.GWO的应用方面
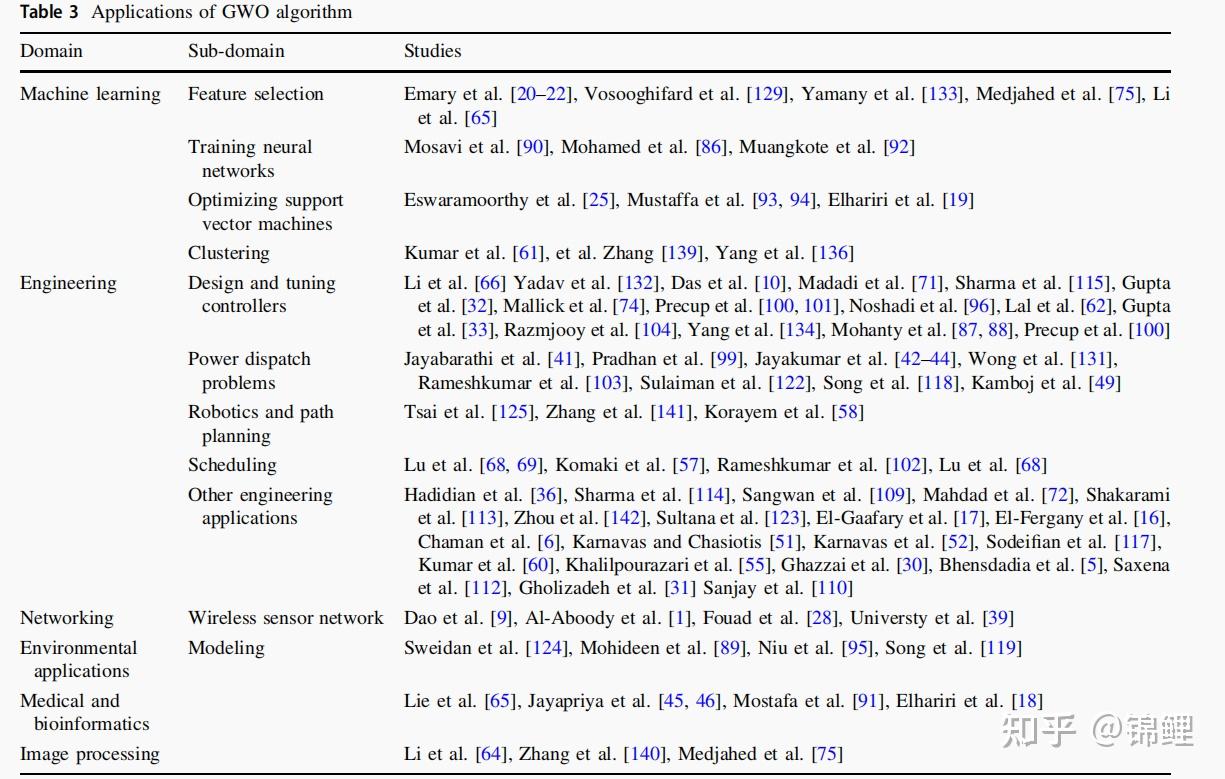
- 机器学习应用:GWO已经被应用于不同的机器学习应用中。这些应用主要分为四类
(1)特征选择。将GWO的二进制版本与k近邻(KNN)结合作为适应度函数来评估特征的候选子集。二进制的GWO基于基因表达数据的癌症分类。特征约简方法,使用GWO在特征空间中搜索特征子集,使基于粗糙集的分类适应度函数最大化。高光谱波段选择的特征选择。将GWO的二进制版本集成为基于包装器的特征选择方法的组成部分,使用核极限学习机作为医学诊断问题的分类器。入侵检测系统中引入了GWO来进行特征选择。
(2)训练神经网络。GWO被用于优化单个隐藏MLP网络的权值和偏差。径向基函数神经网络(RBFN)是另一种流行的神经网络类型,将改进后的GWO应用于一种称为qGaussian径向基函数链接网的RBFNs。
(3)优化支持向量机。应用GWO来调整最小二乘支持向量机(least squares SVM, LSSVM)的变异之一的gamma和sigma超参数。采用GWO算法对支持向量机的惩罚代价参数和核参数进行优化。利用GWO对支持向量机参数进行调整,对肌电图信号进行分类。
(4)聚类应用。基于GWO的聚类算法,克服k-means算法的缺点,GWO中的每个个体代表一个固定数量的质心序列,在适应度评估方面,使用每个数据点与该点的聚类质心之间的欧式距离的平方和。基于Powell局部优化的GWO聚类方法。GWO算法和K-means算法混合,GWO的任务是为k-mean选择初始质心,以克服初始起点的依赖性。
- 工程应用包括
(1)设计和调整控制器(2)电力调度问题(3)机器人技术与路径规划(4)线程调度
- 无线传感器网络
- 环境建模应用
- 医学及生物应用
- 图像处理
7.展望
- GWO算法的主要缺点是处理大量变量的能力和在解决大规模问题时逃避局部解的能力。
- 混合GWO和其他当前的算法可以设计各种模型算法。通过使用其他算法的运算符,可以改进对GWO的探索和利用。
- GWO将群体分成四组,这被证明是解决基准问题的有效机制。在解决具有挑战性的现实问题时,考虑或多或少拥有不同数量狼的分组可以被视为一个研究领域,提高GWO的性能。
- 动态优化:目前尚无文献对GWO算法进行修改或使用来解决动态问题。在动态搜索空间中,全局最优值会随着时间的变化而变化。
- 动态多目标优化:文献中没有关于评估动态变化的工作。对MOGWO的高度探索使得它有可能发现搜索空间的不同区域,但它需要修改以更新非支配解。
- 约束优化:尽管有很多现实世界的问题已经被解决了GWO,目前尚无系统的文献研究该算法的最佳约束处理方法。目前大多使用罚函数,当搜索空间中存在大量不可行区域时,罚函数并不有效。因此,为GWO配备不同的约束处理技术并考察其性能是一个很好的研究方向。
- 二进制优化:文献中有几次尝试解决二进制问题(主要是为了特征选择)。然而,并没有系统性的尝试为这个算法提出一个通用的二进制模型。研究和积分传递函数或其他算子来解决广泛的二元问题。s型和v型传递函数值得研究。
- 多目标优化:虽然MOGWO算法已经开发出了利用GWO算法解决多目标问题的算法,但这里存在几个可以针对性的缺点。MOGWO使用存档,但在文献中还有其他机制来解决多目标问题。因此,建议使用不同的算子(如非支配排序、归档、聚合等方法)来解决多目标优化问题.
- 多目标优化:目前的GWO多目标变量使用帕累托最优优势来比较解。如上所述,归档存储非主流解决方案。该存档对于最多有四个目标的问题是相当有效的。然而,对于许多目标问题,由于大量的非支配解,存档很快就满了。因此,需要有空间算子来解决这些问题(如超大容量、修正帕雷托最优优势)包括组合问题。
- 对GWO算法的主要特性进行详细而全面的理论分析。这些分析包括对种群结构、参数的研究。例如,为什么算法中只有三个leader ?以及当这个数字增加或减少时,性能将如何受到影响。
下面的表格对应参考资料[1]中的参考文献,需要的读者可以由DOI号自行下载。

参考资料:[1]Hossam Faris,,Ibrahim Aljarah,,Mohammed Azmi Al-Betar & Seyedali Mirjalili.(2018).Grey wolf optimizer: a review of recent variants and applications.Neural Computing and Applications(2),. doi:10.1007/s00521-017-3272-5.(1区,高被引论文)
%%算法真实性?有意者可详读参考文献,代码链接:Sooty Tern Optimization Algorithm (STOA) - File Exchange - MATLAB Central (mathworks.cn)
欢迎在评论区进行讨论该算法
1.原理
在迁徙过程中,燕鸥会成群结队。为了避免燕鸥之间的碰撞,燕鸥的初始位置不同。在一个群体中,燕鸥可以向最适合生存的燕鸥的方向行进,即适合度值相对于其他燕鸥较低的燕鸥。根据最适合的燕鸥,其他燕鸥可以更新它们的初始位置。燕鸥在空中攻击时使用扇动飞行模式(即螺旋状运动)。这些行为可以用这样一种方式来表述,它可以与要优化的目标函数相关联。
2.算法数学模型
下面讨论迁移和攻击行为的数学模型:
2.1迁移行为(探索)
在迁徙过程中,燕鸥应满足以下三个条件
- 避免碰撞:
用于新搜索代理位置的计算,以避免相邻搜索代理之间(即燕鸥)的碰撞。
(1)
其中: 表示不与其他搜索代理发生冲突的搜索代理的位置,
表示当前搜索代理的位置,
表示当前迭代次数,
表示搜索代理在给定搜索空间中的移动。
(2)
其中: 是调节
由
到
线性减小的控制变量,
一般设置为2。
- 向最优邻域的方向收敛:避免碰撞之后,搜索代理向最佳邻域方向收敛。
(3)
其中: 表示搜索代理
朝最优搜索代理
不同位置,
是一个随机变量。
(4)
- 更新对应的最佳搜索代理:搜索代理可以更新其相对于最佳搜索代理的位置。
(5)
其中: 表示搜索代理和最适合搜索代理之间的差距。
2.2攻击行为(开发)
在迁徙过程中,燕鸥可以改变它们的速度和攻角。它们用翅膀来提高飞行高度。在攻击猎物时,它们在空中产生如下螺旋行为
(6)
(7)
(8)
(9)
其中: 表示螺旋每一圈的半径,
是常量,定义螺旋的形状,均设置为1,
表示介于
之间的变量,
自然对数的底,因此,搜索代理的更新位置是(6)-(9)。
(10)
其中: 表示更新其他搜索代理的位置,并保存最佳的最优解决方案。
参考文献
[1]Dhiman G, Kaur A . STOA: A bio-inspired based optimization algorithm for industrial engineering problems[J]. Engineering Applications of Artificial Intelligence, 2019, 82(JUN.):148-174.
Take the form of decomposition-coordination procedure (solution of the subproblem is coordinated to the solution of the global problem)
ADMM: benefits of dual decomposition + augmented Lagrangian methods for constrained optimization
Primal problem Lagrangian function is
The dual function is
The dual problem is
. recover a primal optimal point ? from a dual optimal point ?
Solve this dual problem using gradient ascent:
The dual ascent method can lead to a decentralized algorithm in some cases.
If the objective ? is separable,
the Lagrangian function is
, which is separable in ?
. This means that
?-minimization step splits into ?
separate problems that can be solved in parallel.
Solve: So, the ?
-minimization step is carried out independently, in parallel. Each iteration of the dual decomposition requires a broadcast and gather operation [in the dual update, collect
? to compute the residual ?
. Once a global dual variable
? is computed, it will be broadcast to
? individual
? minimization steps. ]
[Book]Cooperative distributed multi-agent optimization (this book discusses dual decomposition methods and consensus problems). Distributed Dual Averaging in Networks (distributed methods for graph-structured optimization problems)
0.3 Augmented Lagrangians and Method of Multipliers augmented lagrangian is to bring robustness to the dual ascent method, and to yield convergence without assumptions like strict convexity or finiteness of ?.
Augmented Lagrangian is . The dual function is
. Adding the penalty term is to be differentiable under rather mild conditions on the original problem.
find the gradient of the augmented dual function by minimizing over ?, then evaluating the resulting equality constraint residual.
Algorithm:
Here, the parameter ? is used as the step size
?.
[The method of multipliers converges under far more general conditions than dual ascent, including cases when ?takes on the value ?
or is not strictly convex.]
- How to choose ?
: The optimality condition is primal and dual feasibility, i.e.,
. Then, we have ?
can minimize ?
, so
So, using
? is dual feasible. --> ? primal residual ?
converges to 0 --> ? optimality.
Shortcoming: When ? is separable, the augmented Lagrangian ?
is not separable, so the ?
-minimization step cannot be carried out separately in parallel for each ?
. This means that the basic method of multipliers cannot be used for decomposition
blend the decomposability of dual ascent with the superior convergence properties of the method of multipliers.
Problem:
Difference: ? splits into two parts, ?
and ?
, with the objective function separable across the splitting.
optimal value: . Augmented Lagrangian:
.
1.1.1 Unscaled form
why ADMM is alternating direction? If use method of multipliers to solve this problem, we will haveSo, the augmented lagrangian is minimized jointly with two variables ?. But, ADMM update ? and ? in an alternating or sequential fashion, --> alternating direction. ADMM can be viewed as a version of method of multipliers where a single Gauss-Seidel pass over ? and ? is used instead of joint minimization.
1.1.2 Scaled form
combine the linear and quadratic terms in the augmented lagrangian and scale the residual variable.
Set ? , the ADMM becomes
Define residual at ?
iteration as
?, we have
.
Assumption 1: function ? and ?
are closed, proper, and convex.
this assumption means the subproblem in ?-update and ?
-update are solvable. allows
are nondifferentiable and to assume value ?
Assumption 2: Unaugmented Lagrangian ? has a saddle point. This means there exists
? such that
.
Based on assumption 1,? is finite for saddle point ?
. So, ?
is solution to ?
. So, ?
and ?,
?. It also implies that
?is dual optimal, and the optimal value of the primal and dual problem are equal, i.e., the strong duality holds.
Under Assumption 1 and Assumption 2, ADMM iteration satisfy:
- residual convergence: ?
as ?
.
- objective convergence: ?
as
- dual variable convergence: ?
as
1.3.1 Optimality condition for ADMM:
- Primal feasibility
- Dual feasibility
Since ?
minimizes ?
, we have
This means that ?
satisfy ?
. Similarly, can obtain other conditions.
the last condition holds for ?, the residual for the other two are primal and dual residuals
? and ?
.
1.3.2 Stopping criteria
suboptimality: shows that when the residuals
?and ?
are small, the objective suboptimality will be small.
It's hard to use this inequality as a stopping criterion. But if we guess ? , we have
.
so, the stopping criterion is that the primal and dual residuals are small, i.e., where
? are feasibility tolerance for primal and dual feasibility conditions. These tolerances can be chosen using an absolute and relative criterion, such as
1. Varying Penalty Parameter
using different penalty parameters ? for each iteration. -> improve convergence, reduce independence on initial ?
.
where
? are parameters. The idea behind this penalty parameter update is to try to keep the primal and dual residual norms within a factor of
?of one another as they both converge to zero.
- large values of
- Conversely, small values of ?
So, when primal residual becomes large, inflates ? by ?
; when primal residual seems too small, deflates
? by ?
. When a varying penalty parameter is used in the scaled form of ADMM, the scaled dual variable
? should be rescaled after updating ?.
2. More general Augmenting terms
- idea 1: use different penalty parameters for each constraint,
- idea 2: replace the quadratic term ?
with
?, where
? is a symmetric positive definite matrix.
3. Over-relaxation in the ? - and ?
- updates
can be replaced with
,
where ? is a relaxation parameter. When ?
, over-relaxation; when ?
, under-relaxation.
4. Inexact minimization
ADMM will converge even when the ?- and ?
-minimization steps are not carried out exactly, provided certain suboptimality measures in the minimizations satisfy an appropriate condition, such as being summable.
in situations where the
5. Update ordering ? -,
?-, ?
- updates in varying orders or multiple times. for example, divide variables into
? blocks and update each of them in turn (multiple times). --> multiple Gauss-Seidel passes.
6. Related algorithms Dual ADMM: applied ADMM to a dual problem. Distributed ADMM: combination ADMM and proximal method of multipliers.
Three cases:
- quadratic objective terms;
- separable objective and constraints;
- smooth objective terms.
Here, we just discuss ?-update, and can be easily applied to
?-update.
where
? is a known constant vector for the purpose of the ?
-update.
If ? , ?
-update is
.
Moreau envelope or MY regularization of ? :
So, the
?-minimization in the proximity operator is called proximal minimization.
for example, if ?, the ?

2.2 Quadratic Objective Terms
, where ?
, the set of symmetric positive semidefinite ?
matrices.
Assume ? is invertible, ?
is an affine function of
?given by
.
1. Direct methods:
If we want to solve?, steps: 1. factoring ?
. 2. back-solve: solve
,? where ?
and ?
, can compute ?
based on
?, then iterates, so can compute ?
, i.e., can compute ?
? is the sum of the cost of factoring ?
and the cost of the back-solve.
In our case, ? , where ?
.
We can form? at a cost of ?
flops (floating point operations). We then carry out a Cholesky factorization of
? flops; the back-solve cost is ?
. (The cost of forming ?
? is on the order of, or more than ?
, the overall cost is ?
? in order, the matrix inversion lemma described below can be used to carry out the update in ?
flops.)
2. Exploiting Sparsity
- When ?
and
- can be more efficient
3. Caching Factorizations ? , If
? is the factorization cost and ?
is the back-solve cost, then the total cost becomes
? instead of
?, which would be the cost if we were to factor ?
each iteration. As long as ? does not change, we can factor ?
once, and then use this cached factorization in subsequent solve steps
4. Matrix Inversion Lemma For efficient computation.
5. Quadratic Function restricted to an Affine Set
Here, ?
is still an affine function of
?. the update involves solving the KKT condition:
If ? is smooth, can use iterative methods. (gradient method, nonlinear conjugate gradient, L-BFGS).
The convergence of these methods depends on the conditioning of the function to be minimized. The presence of the quadratic penalty term ?tends to improve the conditioning of the problem and thus improve the performance of an iterative method for updating ?
- Early Termination Early termination in the ?
- Warm Start initialize the iterative method used in the ?
obtained in the previous iteration
- Quadratic Objective Terms are worth using an iterative method than a direct method. --> conjugate gradient method. Can use when the direct method does not work or
1. Block Separability ? , then ?
. If the quadratic term ?
is also separable, i.e., ?
is block diagonal, then the augmented lagrangian ?
is separable. --> compute in parallel.
2. Component separability
? and
? is diagonal. ?
-minimization step can be carried out via ?
scalar minimization.
3. Soft Thresholding
If ? and ?
, --> component separability. the scalar
?-update is
. Even the first term is not differentiable, but can use subdifferential.
Actually, this is the proximity operator of the ? norm.
停更好久,今天继续我们的算法介绍,今天为大家介绍的是鲸鱼算法(Whale Optimization Algorithm,WOA)[1]。鲸鱼优化算法(WOA)是 2016 年由澳大利亚格里菲斯大学的 Mirjalili 等提出的一种新的群体智能优化算法,因算法简练易于实现,且对目标函数条件要求宽松,参数控制较少等种种优点受到一批又一批学者的亲睐,且经过不断的改进WOA已应用于许多领域。
- 算法介绍
WOA算法设计的既精妙又富有特色,它源于对自然界中座头鲸群体狩猎行为的模拟, 通过鲸鱼群体搜索、包围、追捕和攻击猎物等过程实现优时化搜索的目的。在原始的WOA中,提供了包围猎物,螺旋气泡、寻找猎物的数学模型。在初始每个鲸鱼的位置
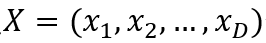
代表了一个可行解,通过后期探索和开发两个阶段,逐步找到最佳位置,即最优解。
首先,座头鲸可以识别猎物的位置并将其包围,但由于最佳位置在搜索空间中不是已的,因此WOA算法假定当前最佳候选解决方案是目标猎物或接近最佳猎物。 确定最佳搜索代理后,其他搜索代理将因此尝试更新其对最佳搜索代理的位置。 此行为由以下方程式表示:
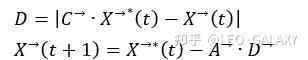

座头鲸还可以使用螺旋气泡发捕捉猎物,该方法首先计算鲸鱼与猎物之间的距离。通过距离创建一个螺旋方程,等式如下:

鲸鱼在选择包围法和螺旋气泡法捕猎是随机的,因此prob我们使用来进行随机选择,公式如下:

当然,在海洋中的座头鲸会在四处寻找猎物,在这里,我们使用随机值大于1或小于-1的A来强制搜索代理远离参考鲸,与开发阶段相反,我们在探索阶段根据随机选择的搜索代理而不是到目前为止找到的最佳搜索代理来更新搜索代理的位置并允许WOA算法执行全局搜索,等式如下:

WOA源代码传送门: SEYEDALI MIRJALILI
本人在改进WOA的过程中,发现本身具有很强的寻优能力,是一个不错的算法,如果真的要改的话可以采用混沌映射,高斯突变之类的在探索阶段进行扰动,但是该算法已经发布好多年了,更多的还是自己新奇想法比较好,传统的改进方法早已被很多研究人员使用。
[1]Mirjalili, S., & Lewis, A. (2016). The whale optimization algorithm.Advances in engineering software,95, 51-67.
8本电子书自取,见文末~
遗传算法原理是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。
粒子群优化算法,缩写为PSO,属于进化算法的一种。和模拟退火算法相似,它也是从随机解出发,通过迭代寻找最优解。它也是通过适应度来评价解的品质,但它比遗传算法规则更简单,它没有遗传算法的“交叉”和“变异”操作,它通过追随当前搜索到的最优值来寻找全局最优。
线性规划单纯形法就是通过设置不同的基向量,经过矩阵的线性变换,求得基可行解(可行域顶点),并判断该解是否最优,否则继续设置另一组基向量,重复执行以上步骤,直到找到最优解。 所以,单纯形法的求解过程是一个循环迭代的过程。
CNN就是卷积神经网络模型,CNN是一种前馈神经网络,通常包含5层,输入层,卷积层,激活层,池化层,全连接FC层,其中核心部分是卷积层和池化层。
优点:共享卷积核,对高维数据处理无压力;无需手动选取特征。
缺点:需要调参;需要大量样本。
RNN是循环神经网络,由输入层、隐藏层、输出层组成。激活函数使用的是tanh函数。
LSTM是循环神经网络RNN的变种,包含三个门,分别是输入门,遗忘门和输出门。
sigmoid函数主要是决定什么值需要更新;
tanh函数:创建一个新的候选值向量,生成候选记忆。
常见的激活函数有:Sigmoid、Tanh、ReLU、Leaky ReLU
Sigmoid函数:
特点:
它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。
缺点:
缺点1:在深度神经网络中梯度反向传递时导致梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
缺点2:Sigmoid 的 output不是0均值(即zero-centered)。
缺点3:其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
Tanh函数:
特点:它解决了Sigmoid函数的不是zero-centered输出问题,收敛速度比sigmoid要快,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
ReLU函数:
特点:
1.ReLu函数是利用阈值来进行因变量的输出,因此其计算复杂度会比剩下两个函数低(后两个函数都是进行指数运算)
2.ReLu函数的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
3.ReLU的单侧抑制提供了网络的稀疏表达能力。
ReLU的局限性:在于其训练过程中会导致神经元死亡的问题。
这是由于函数f(x)=max(0,x)导致负梯度在经过该ReLU单元时被置为0,且在之后也不被任何数据激活,即流经该神经元的梯度永远为0,不对任何数据产生响应。在实际训练中,如果学习率(Learning Rate)设置较大,会导致超过一定比例的神经元不可逆死亡,进而参数梯度无法更新,整个训练过程失败。
Leaky ReLu函数:
LReLU与ReLU的区别在于, 当z<0时其值不为0,而是一个斜率为a的线性函数,一般a为一个很小的正常数, 这样既实现了单侧抑制,又保留了部分负梯度信息以致不完全丢失。但另一方面,a值的选择增加了问题难度,需要较强的人工先验或多次重复训练以确定合适的参数值。
基于此,参数化的PReLU(Parametric ReLU)应运而生。它与LReLU的主要区别是将负轴部分斜率a作为网络中一个可学习的参数,进行反向传播训练,与其他含参数网络层联合优化。而另一个LReLU的变种增加了“随机化”机制,具体地,在训练过程中,斜率a作为一个满足某种分布的随机采样;测试时再固定下来。Random ReLU(RReLU)在一定程度上能起到正则化的作用。
ELU函数:
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
数据的角度:获取和使用更多的数据(数据集增强);
模型角度:降低模型复杂度、L1\\L2\\Dropout正则化、Early stopping(提前终止)
模型融合的角度:使用bagging等模型融合方法。
方法:双指针 + sliding window
定义两个指针 start 和 end 得到 sliding window
start 初始为0,用end线性遍历每个字符,用 recod 记录下每个字母最新出现的下标
两种情况:一种是新字符没有在 record 中出现过,表示没有重复,一种是新字符 char 在 record 中出现过,说明 start 需要更新,取 start 和 record[char]+1 中的最大值作为新的 start。
需要注意的是:两种情况都要对record进行更新,因为是新字符没在record出现过的时候需要添加到record中,而对于出现过的情况,也需要把record中对应的value值更新为新的下标。
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
start=0
dic={}
res=0
for end in range(len(s)):
if s[end]in dic:
start=max(start, dic[s[end]]+ 1)
dic[s[end]]=end
res=max(res, end - start + 1)
return res↓ ↓ ↓以下8本书电子版免费领,直接送 ,想要哪本评论区说声,我小窗给你↓ ↓ ↓


22年Q3最新大厂面试题电子书,部分截图如下:

看了一下十二步CFD入门这篇文章,受益颇多.
但是有一个缺点就是作者这里都是基于结构网格而且是正交网格做的,貌似采用的是有限差分法,对于求解域中间存在边界的情况处理比较困难,比如我就关系中间建筑物对污染物扩散的阻挡效果。尝试过用作者的代码处理我的问题,发现作者的代码在实现对流项的时候还会出问题,但是对于扩散项处理还是很好。
而且作者的思路和商业软件的使用者的常规思路略有不同。
因此在这个基础上,写了一个非结构的有限体积二维求解器。大致思路是先离散求解域,把网格拓扑存成json文件,然后读取这个网格文件获取系数矩阵,之后求解系数矩阵得到数值解,系数矩阵的组装主要参考了openfoam中的方法,复杂的边界和三角形的网格也是可以处理的,拓展到三维也没有问题,而且如果网格数比较大可以上torch,也可以采用遗传算法或者其他的优化算法来求解矩阵。
这里求解的是一个简单的污染物扩散过程,先用正交非结构网格做一版。
大致流程可以分为3步
1.网格划分和初始条件生成
dx=(x_max - x_min) / num_x
dy=(y_max - y_min) / num_y
x=np.linspace(x_min, x_max, num_x)
y=np.linspace(y_min, y_max, num_y)
grid_x, grid_y=np.meshgrid(x, y)
mesh_total=len(x) * len(y)
c=np.zeros((len(y), len(x)))
initial_conditions=np.random.randint(0, len(x), (1, 2)) # 找到这个位置
for i in initial_conditions:
c[i[0], i[1]]=np.random.randint(9, 10, 1)
由于是非结构网格上面肯定不行的,因此这里把网格的拓扑关系存成json字典
for i in range(num_y):
for j in range(num_x):
cell_num=i * num_x + j
if i==0:
cell_face.update({cell_num:[cell_num + num_x + 1, cell_num + 1, cell_num + num_x + 2,
num_x + (num_x + 1) + cell_num + 1]})
else:
cell_num_up=cell_num - num_x
cell_num_start=cell_face[(i * num_x - 1)][-1]+ 1
cell_face.update({cell_num:[cell_num_start + j, cell_face[cell_num_up][-1], cell_num_start + j + 1,
cell_num_start + j + num_x + 1]})2.然后就是做出系数矩阵的过程了
for i in range(num_y):
for j in range(num_x):
cell_num=i * num_x + j
adj=cell_cell[cell_num]
ap=rhoc * dx * dy / dt
b_matrix[cell_num]=b_matrix[cell_num]* ap
for m in adj.keys():
if (adj[m]is not None) & (str(m) in['E', 'W']):
coefficient_matrix[cell_num, adj[m]]=-k * dy / dx
if (adj[m]is not None) & (str(m) in['N', 'S']):
coefficient_matrix[cell_num, adj[m]]=-k * dx / dy
ap=ap - np.sum(coefficient_matrix[cell_num, :], axis=-1)
coefficient_matrix[cell_num, cell_num]=ap
3.之后就是求解了,采用numpy自带的求解工具得到的扩散效果如下
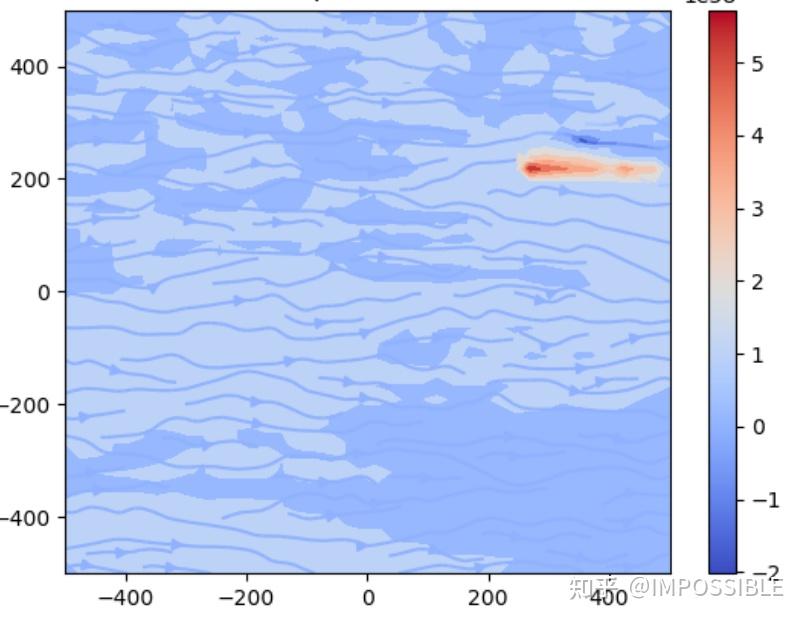
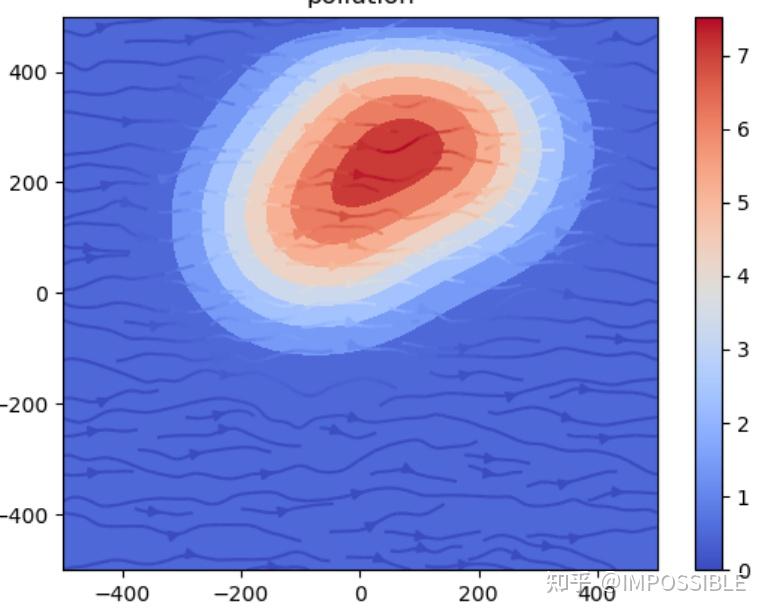
具体的扩散结果
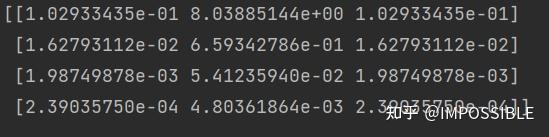
拓展到更大的平面以及添加一些数值稳定的迎风格式求解对流项大致与上面相同,系数的组装而已,后面再写。
这里再补充一下稀疏矩阵的雅克比迭代函数,scipy库中貌似没有。
这个迭代方法收敛的速度还是可以的,四万个网格单扩散方程求解一步不到0.1s。
def Jacobi(A, x, b, n):
# 设Ax=b,其中A=D+L+U为非奇异矩阵,且对角阵D也非奇异,则当迭代矩阵J的谱半径ρ(J)<1时,雅克比迭代法收敛。
times=0
diag_=A.diagonal()
# D=diags(diag_)
L=-tril(A, -1)
U=-triu(A, 1)
D_inv=diags(1. / diag_) # np.linalg.inv(D)
while times < n:
xnew=x
x=D_inv @ (b + L @ x + U @ x)
if abs(x - xnew).max() < 0.000000001:
break
times +=1
return x.flatten()然后采用非正交的结构网格,首先修改到适配三角形的网格,下面是计算的温度扩散过程中某个时间的云图,不过由于每个三角形的面都需要遍历去计算相关的系数,所以这个东西貌似在系数获取这一步要慢很多,相比结构网格来说。
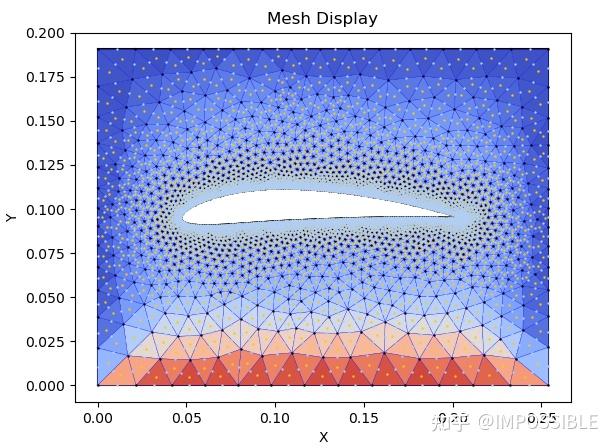
给一个简化的伪代码版本
import matplotlib.pyplot as plt
from coeff_matrix import get_A, get_cell_center_grad, get_b
from meshio import fluentMesh
import numpy as np
from utils import Jacobi
from 网格云图 import plot_value
mesh=fluentMesh('https://www.zhihu.com/topic/ceshi.msh')
bphi=np.zeros(mesh.num_bface) # 边界面的值
c_phi=np.zeros(mesh.num_cell) # 初始值
c_phi[8]=20
inlet=20
outlet=0.5
wall_1=1
wall_2=1
# 将每个面都
bphi[np.arange(mesh.boundary_dict['inlet'][0], mesh.boundary_dict['inlet'][1]+ 1, 1)]=inlet
bphi[np.arange(mesh.boundary_dict['outlet'][0], mesh.boundary_dict['outlet'][1]+ 1, 1)]=outlet
bphi[np.arange(mesh.boundary_dict['wall_1'][0], mesh.boundary_dict['wall_1'][1]+ 1, 1)]=wall_1
bphi[np.arange(mesh.boundary_dict['wall_2'][0], mesh.boundary_dict['wall_2'][1]+ 1, 1)]=wall_2
boundary_value_key=dict(list(zip(mesh.boundary_face_2_global_index, bphi)))
A=get_A(mesh) # 获取系数矩阵A
cell_grad=get_cell_center_grad(mesh, c_phi, boundary_value_key)
b=get_b(mesh, cell_grad, c_phi, boundary_value_key)
c=Jacobi(A, b, c_phi, 100)
print('最小值', c.min())
print('最大值', c.max())
ax=mesh.plot_mesh()
plot_value(mesh, c, ax)
plt.show()继续修改,增加fluent网格处理模块,增加自定义边界模块,增加自定义中间污染物释放源模块。把稀疏矩阵的迭代方式有高斯-赛德尔改为共轭梯度,求解还是可以看,图中大约有1万个网格,单步迭代求解1秒钟,但是获取系数矩阵这一步要20秒。
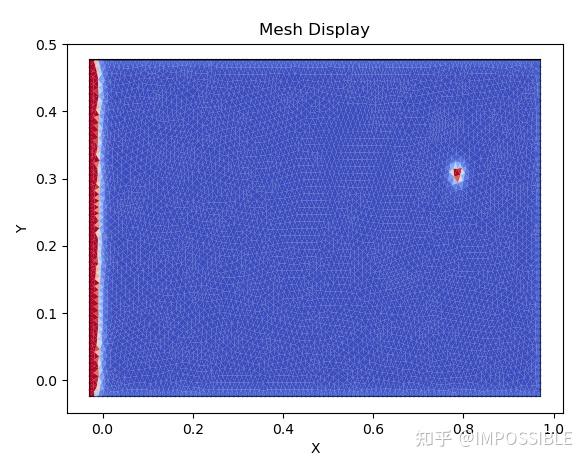
再用c++写了一版,不过只是把系数矩阵获取这一步用c++来写,之后编译成dll库文件,在Python提供的c/c++接口进行调用,发现确实有太大的优势了


看效率一下提高不少呢。


